ネットの書き込み、位置情報、防犯カメラの映像……。世に溢れるケタはずれに大量なデータを経営に活用しようという機運が盛り上がってきた。技術、コストの面での環境も整い、2012年は「ビッグデータ経営」が花開く年となりそうだ。 本誌・深澤 献
ようやく機が熟した!
2012年はビッグデータ元年
ギガ、テラ、ペタ、エクサ、ゼタ、ヨタ……。なにやら怪しげな呪文のようだが、コンピュータのデータ量などを表す“接頭辞”である。ヨタというのは10の24乗。まさに天文学的なケタ数だ。
ベートーベンの名曲集は20ギガバイト、米国議会図書館の蔵書は10テラバイト、全世界の印刷物は200ペタバイトで収まるという。そして21世紀に入り、この世界にはデジタルデータが大量に出回り始めた。その総量はエクサバイトの単位を超え、ゼタバイトのレベルに達している(いずれもカリフォルニア大学バークレー校による試算)。
 出所:UC berkeley,School of information Management and Systems
出所:UC berkeley,School of information Management and Systems 拡大画像表示
この超大量のデータ、すなわち「ビッグデータ」をいかに活用するか。それが、昨今のICT(情報通信技術)のキーワードだ。
ただ、重要なのは「量」だけではない。どんなデータが増えているのかという「質」である。
たとえば今、ほとんどの携帯電話にはGPS(全地球測位システム)が搭載され、定期券などとともに電子マネー機能も備えている。そのため、どこで誰がどんな消費をしたか、捕捉しやすくなった。メールやeコマースでの購買履歴はすべてクラウド上に保管されているし、ツイッターやフェイスブックなどのソーシャルメディアで、自分の行動を発信する人も増えた。店頭や街角にある監視カメラは常に人びとを映し続けている……。
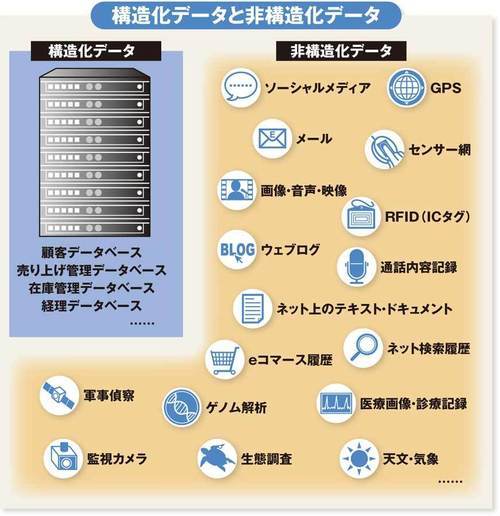
多くの企業がすでに保有している顧客データベースや売り上げ・在庫管理データベースのように、「構造化」(整理)されたデータに比べ、人類が日々生み出し、ゼタバイトの規模にふくらみつつある多様なデータの8~9割は、「非構造」であるといわれる。しかし、この厄介な「非構造化データ」も、従来に比べると驚くべき低コストで、しかも簡単に収集・蓄積・分析できるようになった。
「5年前までは1テラのデータストレージ(記憶装置)は1億円、100テラなら100億円した。それが今は、ほとんどタダ同然で使える。分析にはスーパーコンピュータが必要だったが、そうしたコストも100分の1程度まで下がっている」(仲田聰・EMCジャパン・データ・コンピューティング事業本部テクノロジー&プロフェッショナルサービス部長)
また、ウェブのログデータなど、ノイズの多い非構造化データの傾向値をまとめ上げるには、「Hadoop(ハドゥープ)」というソフトが使われる。もともとグーグルが持っていた大規模分散処理技術をヤフーがオープン化し、無償で使えるようにしたものだ。
「データを収集し、分析する」というのは、別段新しい発想ではないが、その質と量が変わり、分析手法なども整備され、さらにコストも格段に下がっているのだ。
振り返れば、インターネットも1960年代から存在していたが、90年代以降に回線とコンピュータが高速化したことで、実用化が花開いた。ビッグデータも、「この10年でさまざまな環境が整った」と野村総合研究所の鈴木良介主任コンサルタント。ようやく機が熟した。2012年は、まさにビッグデータ元年となるだろう。



