「機械学習」の分野で、大きなブレイクスルーを起こしたという「ディープラーニング」。しかし、ディープラーニングには「過学習」という弱点があると山本一成さんは指摘します。これは人間に例えると「どんな問題も丸暗記で解こうとする応用の利かない人」のようなもの。この弱点を避けるためにはどうすればいいのでしょうか。
新刊『人工知能はどのようにして「名人」を超えたのか?』では、将棋や囲碁を例に、AIにおいて最も重要な技術「機械学習」「深層学習」「強化学習」の本質を解説しています。今回はそのなかから特別に一部を公開します。

すべての人工知能研究者が恐れる
「過学習」とは
誕生から10年がたち、ディープラーニングは著しく複雑化しました。一定の規模のディープラーニングでは、もう全体がどのような理屈で動いているかを明確に説明できる人はいないでしょう。
もちろん細部や個別のしくみは理解できているのですが、それらを組み合わせると、なぜ今のパフォーマンスを発揮できるのかが、わからないのです。
ディープラーニングは、その存在自体が黒魔術のようになっている、と言うこともできます。
またディープラーニングにおいては、層がディープになってもちゃんと機能するよう、無数の黒魔術も生み出されました。
これらも人工知能の進化に欠かすことのできない技術なのですが、そのすべてを伝えるのは本書の趣旨から外れてしまいます。ここでは1つだけ、「ドロップアウト」という黒魔術の概要だけを皆さんにシェアしてみましょう。
ドロップアウトとは、一言でいえばディープラーニングの「過学習」を防ぐ技術です。過学習は、ディープラーニングを理解するうえで重要な概念なので、そこから説明しますね。
ディープラーニングは本当にすごい武器です。正確にはすごすぎる武器です。画像として認識できるものなら、どんな入力と出力のペアでも学習できるのでは、と言われるくらいです。
でも、入力と出力のペアを丸暗記させてしまってはダメですよね。どれほど丸暗記したところで、未知の将棋の局面がこれからいくらでも出てくるのですから。
しかし、ディープラーニングは放っておくと「丸暗記」で解決しようとします。5万個のコップの写真(データ)があったら、その5万個の形をそのまま暗記し、絶対に間違えないように努力してしまいます。この状態を専門用語で「過学習」と言うのです。
 図4 ディープラーニングの難題「過学習」
図4 ディープラーニングの難題「過学習」能力がありすぎるディープラーニングは問題を「丸暗記」して解いてしまう。
丸暗記したディープラーニングは、学習した問題を非常によく解けるようになります。一方で、まったく未知の問題には、丸暗記すればするほど正解率が落ちていきます。これがすべての人工知能の研究者が恐れる「過学習」の状態です。
テストや受験のときの記憶が蘇った方もいると思いますが、人間でもコンピュータでも、丸暗記はダメなんですね。
では、どのようにすれば「過学習」を防げばよいでしょうか。
それには、ディープラーニングが暗記ではなく、特徴を抽出するように仕向ければいいのです。つまり、何かしらの本質をつかめる状態にするとよいということです。
そこで出てくるのがドロップアウトです。
ドロップアウトという言葉は、日本語の会話でもたまに使われますよね。組織などから「ドロップ」する、つまる「抜ける」という意味です。
それと同じく、ディープラーニングが学習中に、ところどころ参加しているニューロンをランダムにドロップアウトさせるのです(ここで言うニューロンは、ディープラーニングの各層における、人間の脳のニューロンに当たるものを意味しています)。
 図5 ドロップアウトのイメージ
図5 ドロップアウトのイメージディープラーニングの学習中に、ランダムに素子を離脱(ドロップアウト)させる。
学習中にランダムにニューロンをドロップアウトさせられることは、当たり前ですがディープラーニング側にとって厳しい状態です。とても「丸暗記」はできません。そこでディープラーニングは、必死になって入力の特徴をつかもうとするのです。
このように書くと「そんなものか」と思われるかもしれませんが、なぜドロップアウトさせると、ディープラーニングは必死になって入力の特徴をつかもうとするのか、正確な説明はとても難しい。まさにこれも黒魔術なのです。
力がありすぎるディープラーニングをわざと学習困難にして、逆にその実力が発揮できるようにする、というのはとてもおもしろい考え方ですよね。
(最後に付け足しで。ドロップアウトは、あくまで多数あるディープラーニングの黒魔術の1つです。しかし大筋では、ディープラーニングの黒魔術たちは過学習を防ぐことを大きな目標としているものが多いようです。)
今、ディープラーニングは
どれくらいのことができるのか?
それでは、黒魔術の塊であるディープラーニングは、今どれくらいのことができるのでしょうか?
現在ディープラーニングの活躍の場はどんどん広がっており、私にも全貌を把握するのは困難です。しかも日々、新しい技術が生まれていると言っても過言ではない状態です。
そのためディープラーニングの今後を占うことは困難ですが、「言葉」と「音声」と「画像」が大きな応用先であることは間違いないでしょう。なぜなら、人間にとってもこの3つの入力と出力が知能の発展に極めて重要でだからです。
当然、これらの入力と出力は経済やビジネス的な観点からも非常に重要です。そしてディープラーニング以外の方法論でこれらを解決するのは、(少なくとも現在は)相当に困難です。以下、3つを順番に見ていきましょう。
■言語
まずはディープラーニングの「言語認識」の技術です。
グーグルが以前より「グーグル翻訳」として、さまざまな言語間の翻訳サービスを運用していたのはご存知だと思います。このグーグル翻訳で、2016年11月よりディープラーニングが使われるようになったのです。
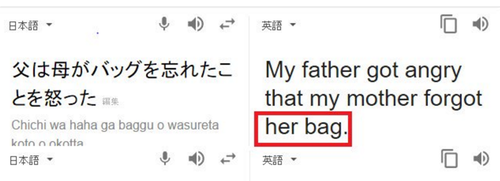 図6 グーグル翻訳の表示(2016年12月5日時点)
図6 グーグル翻訳の表示(2016年12月5日時点)日本語にはなかったカバンの所属に関する情報を自動的に付与している。
図6を見てください。ディープラーニングが導入されたグーグル翻訳の画面です。
「父は母がバックを忘れたことを怒った」と、日本語では誰のバックであるか明示的には書かれてはいません。
それが英語だと「My father got angry that my mother forgot her bag.」 となり、バックに関する情報をディープラーニングが適切に付与しているのがわかります。
従来版のグーグル翻訳も機械学習の手法を取り入れていたのですが、そのときには不可能な翻訳でした。
それが、ディープラーニングを採用した新モデルでは、同じ文のほかの単語とのつながりを基に文脈を学習し、全体を見てそれぞれの単語をどのように訳したらよいのかを決める仕組みになりました。
これによって言語間に構造的に存在する情報の不均一を見事にカバーし、従来版よりも正確度の高い訳文の候補を見つけ出せるようになったのです。
現在ディープラーニング翻訳の実力はかなり上がってきており、口語ではない文章はそろそろ実用レベルが見えてきたかもしれません。
■音声
次はディープラーニングによる「音声認識」の実力の確認です。
現在、英語や中国語などの言語では音声によるスマートフォンへの入力はかなり一般的になっていますが、日本では、日本語の五十音の文字列がスマートフォンでのフリック入力に適しているおかげもあって、あまり利用されていないようです。
しかしこの音声入力の精度は、すでに相当なレベルに達しています。
音声入力にディープラーニングを取り入れたグーグルは、わずか1年で音声認識の誤認識率が23%から8%に下がったことを発表しました(2015年5月時点)。
また、2016年11月の半導体メーカーNVidiaの記事によると、マイクロソフトの研究者チームが音声認識の誤認率を5.9%にまで下げたことを発表しています。
実際、私もスマホで日本語入力をしばしばおこなうのですが、徐々にその精度が上がっていることを実感しています。
この数字はこれからも改善されるでしょう。しかし、音声認識で大きなブレイクスルーを起こすには、あとで説明する「マルチモーダル」的な進歩をへて、人工知能が文脈を理解するようにならなければないのではないか、と個人的には考えています。
■画像
最後に、ディープラーニングの「画像認識」の実力を見ていきましょう。
ディープラーニングにおいて画像は花形と呼べるものです。画像にコップやゴリラが写っているかを正しく判断することはもはや朝飯前です。今はそういったレベルだけではなく、写っている猫や花の種類は何かを特定することも可能になってきました。
また画像の判定だけではなく、画像を入力にして画像を出力するということも可能です。画像を入れて画像を出力することにいったいなんの意味があるのかと読者の皆さんは思うかもしれません。
しかしたとえば、白黒画像を入れて、色がついた画像が出力されたらどうでしょうか? 現実にすでにそういった研究が多くなされていて、過去のモノクロ写真・映画が着色された例が多くあります。
また線画から着色するという技術支援もおこなわれており、すでにウェブサービスも運用されています。近い将来には、漫画家の仕事から色塗りというものが消えてしまうかもしれません。
ほかの機械学習の手法にないディープラーニングの特徴は、自由度の高い入力や出力の設計です。たとえば入力を音声にして、音声に適して画像を出すこといったこともできますし、画像を入力して、適切な説明文を出力することもできます。
こういった考えを「マルチモーダル」といいます。まだ、最先端の人工知能でも入力と出力のルートは限られていますが、もし画像・文字・音声という「入力→出力」の経路を自由に選ぶことができ、しかもそれが正確だとしたら、もはや多くの人がそれを知能と認めざる得なくなるはずです。
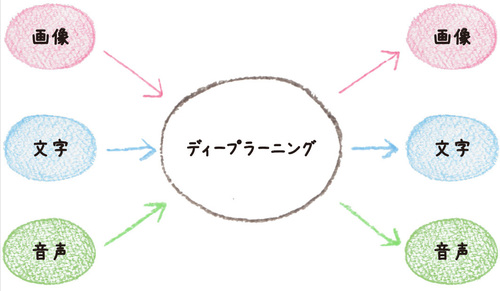 図7 マルチモーダルが可能なディープラーニング
図7 マルチモーダルが可能なディープラーニングさまざまな入力と出力を統一的に扱うディープラーニングは 知能の大統一理論になれるか?
【ダイヤモンド社書籍編集部からのお知らせ 】
 山本一成:著 価格(本体):¥1500 +税 発行年月:2017年5月 判型/造本:46並製、288ページ ISBN:978-4-478-10254-1
山本一成:著 価格(本体):¥1500 +税 発行年月:2017年5月 判型/造本:46並製、288ページ ISBN:978-4-478-10254-1
2017年4月1日――人工知能「ポナンザ」が現役の将棋名人に公式戦で初めて勝利した日を、その生みの親である著者は次のように振り返ります。
「この日は、コンピュータ将棋の世界にとって記念すべきものになりましたが、同時に改めて、人間と人工知能の違いを認識させられた日ともなりました。
本書で紹介してきた人工知能(ポナンザ)の特徴と、世界に意味を見つけ物語を紡いで考えていく人間の思考法の限界が明確に表れたのです。」
本書の魅力は、このフレーズに象徴される「人工知能と人間の本質的な違い」
そして「知能と知性の未来」を、
◇プログラマからの卒業
◇科学からの卒業
◇天才からの卒業
◇人間からの卒業
という4つの章で見事に段階的に説明している点にあります。
そしてもう1つの読みどころは、著者が研究の最前線で遭遇した驚くべき事象や、
囲碁・将棋のプロ棋士たちの人工知能への反応をビビッドに記述していること。
◇黒魔術化する人工知能
◇黒魔術の1つ、「怠惰な並列化」とは
◇ディープラーニングは 知能の大統一理論になれるか?
◇サイコロにも知能がある!?
◇囲碁は画像だった!
◇知能の本質も画像なのか?
◇科学が宗教になる瞬間を見た
◇研究者は「人工知能の性能が上がった理由」を説明できない
◇人類はこれから、プロ棋士と同じ経験をする
などなど、目からウロコの解説の連続で、既存のどんな人工知能の解説書よりも面白くてわかりやすい、必読の1冊となっています。
紙の書籍はこちらから!→[Amazon.co.jp] [紀伊國屋書店BookWeb][楽天ブックス]
電子書籍はこちらから!→[kindle][kinoppy][kobo]
【目次抜粋】
第1章 将棋の機械学習――プログラマからの卒業
将棋の名人を倒すプログラムは、名人でなければ書けないのか?
人間の思考を理解するのは諦めた
電王戦
プログラマからの卒業 …など
第2章 黒魔術とディープラーニング――科学からの卒業
黒魔術化しているポナンザ
ディープラーニングで人工知能が急速に発展する
ディープラーニングと知能の本質は「画像」なのか?
還元主義的な科学からの卒業 …など
第3章 囲碁と強化学習――天才からの卒業
強化学習とは何か
サイコロにも知能がある!?
アルファ碁が示したこと「囲碁は画像だった」
科学が宗教になる瞬間
天才からの卒業 …など
第4章 倫理観と人工知能――人間からの卒業
「目的を持つ」とは意味と物語で考えるということ
人工知能はディープラーニングで知性を獲得する
人工知能は人間の倫理観と価値観を学習する
シンギュラリティと「いい人」理論 …など



