前回の「製造業におけるビッグデータ活用の盲点と対策(1)」では、製造業におけるデータ活用の盲点として、製造業における品質管理プロセスの課題と、暗黙知・経験値で執り行われている業務こそAI化の価値がある点について説明しました。企業が持つ暗黙知、経験値こそ企業しいては日本の英知であり、継承してくべき資産だと考えます。本稿では、暗黙知・経験値を形式知化(AI活用)していくにあたっての具体的な取り組み方、得られる効果、次世代UI技術(AR/MR)を用いたさらなる業務高度化について言及します。
形式知化の取り組み方
経験値・暗黙知で執り行われている業務とは、その名の通り、有識者や熟練者個人が蓄積してきた過去の経験・知見、価値観に基づいた業務であり、以下のような状態と言えます。
第三者による情報の利活用が困難な状態であること
第三者による業務実行結果の再現性がない状態であること
KPMGでは、暗黙知を形式知化するということは、AIにより暗黙知を再現可能な状態にする、ということと定義づけています。これらを形式知化していくためには、具体的にどのようなアプローチで進めていくべきでしょうか。本稿では、製造業の品質管理の観点で具体的な取組みについて整理します。
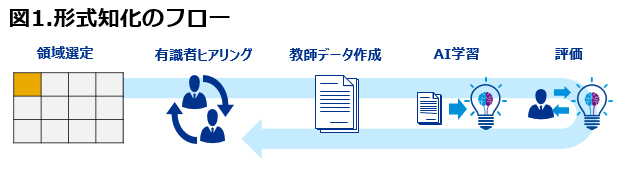 出典:KPMGコンサルティング
出典:KPMGコンサルティング
図1は、進め方の具体的なイメージです。まず、形式知化したい領域を選定し、有識者より過去の実績をデータ収集します。領域は、技術領域毎、製品種別毎、機能種別毎等様々な切り方が考えられますが、AIに学習させるにあたってデータが充実している領域から着手していくのが良いと考えます。



