このような方法は、昔から機械学習の分野では使われていました。けれども、ディープラーニングの技術が開発されたことで、それまでとは別次元で本物に近い顔を生成することができるようになりました。図5-2の写真を見てください。これは、最新の生成モデルによってつくられた顔です。
 同書より 拡大画像表示
同書より 拡大画像表示
本物の人間を撮影したような写真ですが、すべて現実には存在しない人物の顔です。このように最近の生成モデルがつくり出す顔は、本物と言われても疑うことがないぐらい技術が進歩しています。そして、その突破口となった研究が2014年に発表されたGANという生成モデルです。
ノイズ画像から顔を生成する
敵対的生成ネットワーク
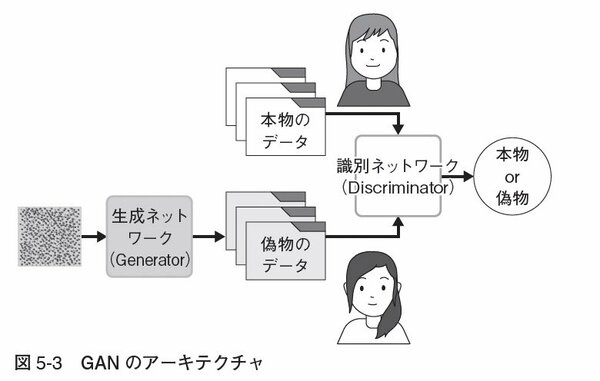
カナダにあるモントリオール大学の博士課程の学生だったイアン・グッドフェローは、ただのノイズ画像から顔を生成するという、まるでマジックのような、まったく新しい人工知能のアーキテクチャを提案しました。その名も、敵対的生成ネットワーク(Generative Adversarial Networks)、頭文字をとってGANと名付けられました。敵対的という言葉が入っているのは、生成ネットワーク(Generator)と識別ネットワーク(Discriminator)と呼ばれる2つのネットワークを競い合わせることで、より本物に近い画像をつくり出すよう生成ネットワークが学習していくからです。
 同書より 拡大画像表示
同書より 拡大画像表示
図5-3を見てください。生成ネットワークには最初、ノイズ画像が与えられます。それをもとに、顔にできる限り近い偽物の画像をつくり出して識別ネットワークに渡します。識別ネットワークの方は、別に与えられた本物の顔の画像と比べて、どちらが本物かを判断します。識別ネットワークが偽物の顔画像を本物と間違えるまで、生成ネットワークは、試行錯誤しながら、顔っぽく見える画像をつくり出す方法を求めて、自身のネットワーク構造を変化させていきます。この試行錯誤を膨大な回数繰り返すうちに、最後にはノイズから本物と見間違う顔をつくり出す生成ネットワークができてしまうのです。
ただ、完璧に見えるGANにも、いくつか問題がありました。まず、上手く学習させることが難しいという問題です。ただのノイズ画像から、行き当たりばったりで顔らしきものを生成する「出たとこ勝負」のネットワークなので、動作の不具合や学習が不安定になることが多く、かなり高度なAIの開発技術を持った人でないと、本物と見間違えるような顔を生成するネットワークをつくることが難しいとされています。







