「すべての科学研究は真実である」と考えるのは、あまりに無邪気だ――。
科学の「再現性の危機」をご存じだろうか。心理学、医学、経済学など幅広いジャンルで、過去の研究の再現に失敗する事例が多数報告されているのだ。
鉄壁の事実を報告したはずの「科学」が、一体なぜミスを犯すのか?
そんな科学の不正・怠慢・バイアス・誇張が生じるしくみを多数の実例とともに解説しているのが、話題の新刊『Science Fictions あなたが知らない科学の真実』だ。
単なる科学批判ではなく、「科学の原則に沿って軌道修正する」ことを提唱する本書。
今回は、本書のメインテーマである「再現性の危機」の実態に関する本書の記述の一部を、抜粋・編集して紹介する。
「データ同士を線で結ぶ」ときの落とし穴
図3は過剰適合の例だ。ここに1年間、毎月1回、測定した降雨量のデータセットがある。これらのデータを線で結び、降雨量の変化を示したい。
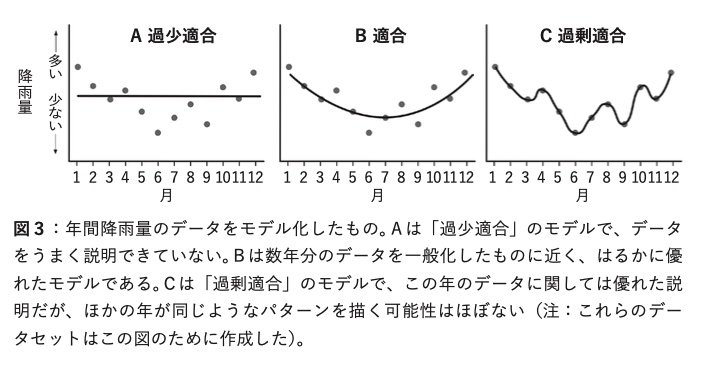
この線がデータの統計的モデルになり、それをもとに1年後の月ごとの降雨量を予測しようとしている。手っ取り早いのは図3Aのような直線だが、これではデータと似ても似つかない。この直線を使って来年の降雨量を予測すれば、毎月まったく同じ量の雨が降ることになり、ひどく不正確な予測になる。次に図3Bのようにデータを通る曲線を引いてみると、それなりの近似になって、次の年の予測をするために有効なモデルと言えるだろう。
ただし、ここでやめないと危険なことになる。図3Cのようにすべてのデータポイントに触れる線を描くと、曲がりくねって進む。このモデルは今回のデータセットにはぴたりとフィットするが、来年のデータがまったく同じ浮き沈みをする可能性はどのくらいあるか。高いとは言えない。線をすべての点に合わせることは、データセットに存在するランダムなノイズをモデル化しているだけだ。このモデルはデータに過剰適合している。この図は過剰適合の例だ。