統計学の解説書ながら42万部超えの異例のロングセラーとなっている『統計学が最強の学問である』。そのメッセージと知見の重要性は、統計学に支えられるAIが広く使われるようになった今、さらに増しています。そしてこのたび、ついに同書をベースにした『マンガ 統計学が最強の学問である』が発売されました。本連載は、その刊行を記念して『統計学が最強の学問である』の本文を公開するものです。第29回では、「言葉」を分析するテキストマイニングについて解説します。(本記事は2013年に発行された『統計学が最強の学問である』を一部改変し公開しています。)
 Photo: Adobe Stock
Photo: Adobe Stock
計量文献学が否定した「シェイクスピア=ベーコン説」
テキストマイニングとは、ひと言で言えば自然言語で書かれた文章を統計学的に分析することである。なお自然言語とは、日本語や英語のような、プログラミング言語のように人工的に作られたわけではないふつうの言語のことを指す。
従来あるいは現代においても、文章の分析は数学をほとんど使わず、歴史的資料の検討と、哲学的な思索と、文学的な想像力によって支えられてきた。私の周りにも「数字が苦手だから」という理由だけで文学部に進学した人が何人かいるが、仮に数字が苦手でもシェイクスピアの戯曲における表現をベン・ジョンソンの詩と比較して論じることに問題はない。
だが、文章の分析に数が持ち込まれるようになった歴史は意外に古く、19世紀頃から行なわれている。すなわち、文章中に登場する単語の種類や長さ、1つの文の間に含まれる平均的な単語数といった数を数えることによって、文献の特徴を捉えようとする試みがなされるようになったのだ。こうした研究のことは計量文献学と呼ばれるようになる。
初期の計量文献学の研究者もシェイクスピアの文体を分析しようとした。彼の戯曲の美しさの秘密を知ろうとしたわけではなく、彼が本当はフランシス・ベーコンではないか? という当時まことしやかにささやかれていた仮説を検証するためにだ。
なぜそんなことを、と思われるかもしれないが、「シェイクスピアという人物は実在しないのではないか」「誰かのペンネームではないか」といった議論は、18世紀からしばしば繰り返されていたらしい。彼が平民の出自であるためあまりに歴史的資料が少なく、またその割に貴族の文化や教養を描くのがうまいため、誰か別の教養ある人物が作品を執筆していたのではないか、というのである。
なお、フランシス・ベーコンはシェイクスピアと同時代に生きた偉大な哲学者であり、偏見や先入観を減らし、観察と実験によって真理にたどり着く帰納的推計の重要性を説いた統計家なら間違いなく尊敬すべき人物だ。彼であれば文章力や教養において、シェイクスピアの戯曲を書くに足る人物であると思われたのかもしれない。
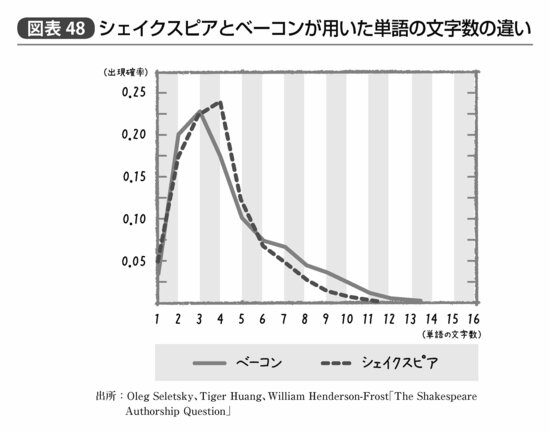
そして両者の文章の比較が行なわれた結果、平均的な単語の長さや1文中の単語の数が同様とは言いがたい、という結論が得られた(図表48)。戯曲と哲学的書籍の文体が変わるのは当たり前だろうという批判もあるが、とりあえず「巷で言われているほど特に共通した特徴は見られなかった」という結果が、文章の数値的特徴から示唆されたというのは大きな進歩である。
テキストマイニングの王道「形態素解析」とGoogleを支える「N-Gram」
19世紀に本1冊分の文章に登場する単語の数や文字数をカウントする、というのはおそらく地獄のような作業だっただろう。しかしながら、ITが発達した現代であればそれほど大した手間ではなくなった。今では多くのオープンソースの形態素解析ツールが公開されており、それを用いれば、文章中の単語の使用頻度の分析や、動詞か名詞かという品詞別の集計、2つの文章間での使用単語の類似性の分析などが簡単に行なえる。
形態素解析とは一般的に、文章を単語ごとに分割し、どのような単語が何度使われているかを集計する作業のことを言う。なお言語学的な用語として、「形態素」とは単語よりも短い、「言語における意味を持つ最小の単位」を指す。たとえば「不安定な」という形容動詞は「不」という打ち消しを示す部分と、「安定」という部分と、「な」というその単語が形容動詞であることを示す形態素に分けることができるが、実用上ここまで分割してしまうと逆にわけのわからない結果になってしまうためか、多くの形態素解析ツールが単語レベルまでの分割にとどめているようである。
形態素解析のためには、まず単語の情報が整理された辞書データが必要になる。基本的には文章内から辞書データ内の単語と一致するものを探し、見つかればフラグを立てる、というアルゴリズムが中心となっているからだ。
実際にGoogle日本語入力開発者の1人である工藤拓によって作られたMeCabという形態素解析ツールによって、「あえて断言しよう。あらゆる学問のなかで統計学が最強の学問であると。」という文章を形態素解析してみると、図表49のような答えが返ってくる。
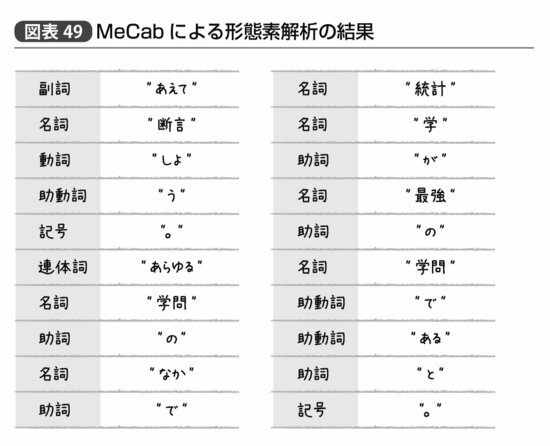
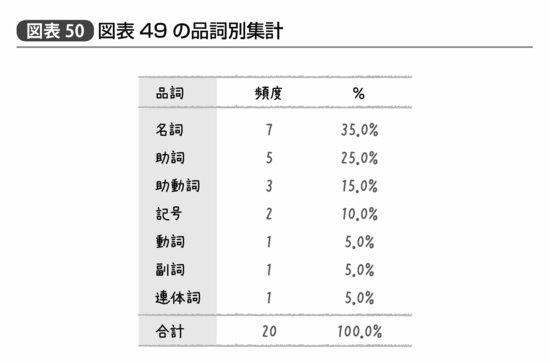
「統計学」は一語の名詞にしてほしかったところだが、悪くない結果である。この結果を品詞別に集計したとすれば図表50のようになるだろう。
ちなみに形態素解析とは異なるアプローチとして、辞書を使わないN-Gramと呼ばれるやり方もある。これはすなわち機械的に重複を許したN文字ずつの文字列を切り出し、そこから求める単語を探すというやり方だ。もしNが5だとすれば「統計学が最強の学問である。」という文章からは、「統計学が最」(1-5文字目)、「計学が最強」(2-6文字目)「学が最強の」(3-7文字目)…「問である。」(最後の5文字)といった5文字ずつのGramが生成される。
先ほどの形態素解析では「統計学」という単語が辞書に存在していなかったため「統計」と「学」が別の単語として認識されていた。そのため形態素解析済みの結果に対して、「統計学」という単語の有無を調べると、「そんな単語は存在していません」ということになってしまう。一方、N-Gramであれば、5文字というGram以下の文字数である「統計学」という単語について、元の文章中に存在する限り確実に発見される、というメリットがある。Googleで、あまり一般的でない単語を検索しても該当するページにヒットするのは、その背後に膨大な量のN-Gramデータが存在しているからだ。
ビジネスにおけるテキストマイニングの活用法
このようなテキストマイニングに携わる専門家は、大きく2つに分けられる。
1つは文学や歴史学、社会学といった人文学系の教育を受けた者、あるいはそうした背景を持った教員に指導されたものである。彼らはしばしば自分の研究のために、テキストマイニングツールを使って資料の見通しをよくしたり、自説の傍証にしたりしようとする。
2つめの立場は、IT的な側から自然言語処理というテーマに興味を持つ者である。彼らはどちらかというとデータマイニングの専門家と近い立場で、人間が1つ1つ確認すれば確実に行なうことのできる形態素解析という作業を、機械的なアルゴリズムで高速かつ正確に行なうためにはどうすればいいかという研究を積み重ねている。
たとえば単純な辞書との一致検索だけでなく、前後の単語が何かという情報を使って推定精度を上げるためにはどうすればよいか、といった研究が彼らの関心である。また、形態素解析された結果をデータマイニングするという研究もよく行なわれている。
こうした技術のビジネス領域における応用例として比較的昔から行なわれてきたのは、カスタマーサポートセンターに対する問合せ内容の分析である。通話終了後にオペレーターが書く報告書や、問合せの電子メールに対して、頻出語の集計やクラスタリングを行なえば、「どのような内容の問合せが多いか」が明らかになる。それさえわかれば対応マニュアルやFAQの整備によってオペレーターの人件費を削減できるのだ。このような取り組みはIBMをはじめさまざまな会社で行なわれてきた。
さらに、送られてきた問合せメールに対して自動的に形態素解析を行ない、登場するキーワードから関係していると思われるFAQをオペレーターの端末上に表示する、というシステムを導入しているところもある。ほとんどの問合せに対してオペレーターはレコメンドされたFAQをコピペすればいい、となれば手間は大幅に削減されるというわけだ。
また、アンケートの自由解答欄に登場する単語を集計する、という取り組みもよく行なわれる応用例の1つである。
顧客の数が増えると自由記述の文章で寄せられる意見全部に目を通すことが困難になるが、形態素解析を行なって単語の出現頻度を集計すれば全体像の把握がずいぶん楽になるのだ。
近年ではこうしたテキストマイニングの応用方法は自社に集まった問合せやアンケートの内容だけでなく、SNSを通じて生みだされる膨大なテキストに対しても行なわれるようになった。自社名や自社商品名を含むブログの記事やツイートはそれ自体重要な「顧客の声」であり、すべてに目を通すことは難しくても、テキストマイニングを通してその全体像を把握すれば、思わぬ新商品やプロモーションキャンペーンのアイディアに繋がるかもしれないのである。
テキストマイニングを活かすコツは、それ以外の統計リテラシー
だが、統計家の視点からテキストマイニング分野に共通した課題を指摘するとすれば、彼らはしばしば自然言語だけにフォーカスしすぎである、という点が挙げられるだろう。
形態素解析を行なえば、確かに文章という非構造化データを単語の出現有無というダミー変数に変換することができる。これによって文章を統計学的に処理できるようになったというのは素晴らしい進歩だが、単純集計や分類によって全体像を把握するというだけではあまりにもったいない。文章中にどのような単語がどのような組み合わせで登場するか、という情報はたいていの場合、すべて膨大な数の説明変数とはなっても、求めるべき結果ではないのだ。
しかしながら、実際に我が国のビジネス分野における応用事例の中でも、テキストマイニングを価値に繋げるような取り組みはすでになされている。
たとえば営業日誌をテキストマイニングし、成功事例と失敗事例の間にどのような単語頻度の違いがあるかを分析し、機会損失を減らすという研究がある。有価証券報告書に登場する単語を分析して、その後倒産する企業と倒産しない企業の間にどのような単語出現頻度の違いがあるかを分析した者もいる。店舗に対するロイヤルティの程度と、その店舗に対してどう思うかの自由記述欄の回答を合わせて分析し、ロイヤルティの高さに繋がるのはどのような単語であるか、という分析を行なった者もいる。いずれにしても、文章中の単語の出現頻度だけでなく、文章の外にある何らかの結果変数との関係性を分析したからこそ、価値を生む戦略が見えるのである。
テキストマイニングの背後にある技術は高度なものだが、その利用自体はツールを使えば誰でも簡単にできるものである。そしてそこからどう価値を生むか、ということになると、テキストマイニング以外の統計リテラシーが重要になるのである。
▶『マンガ 統計学が最強の学問である』の刊行に寄せて
『マンガ統計学が最強の学問である』は、言語化・定型化された仕事がAIに奪われていくなかで、「新たに何をするか考えて決める」スキルを日本に最大限広げるために制作されました。
実は初代『統計学が最強の学問である』はほとんど数式を使わず、統計学がどう生まれてどう役に立てられるのかにフォーカスした、統計学の本としては少し変わった本でした。しかし、40万部以上売れただけあって、あの本を読んで統計学を面白いと感じ、本格的に勉強しようとしたり、実務に活かすようになった、という方と私は日々の仕事の場で頻繁にお会いします。統計手法の数理面を細かく説明したり、統計解析をおこなうためのプログラミングに関する本は多数ありますが、それはちょうどAIのサポートが手厚くなっている部分です。今の時代はそれよりも、「統計学を活用したい」というモチベーション、「どのような課題に対して統計学を活用するか」という課題設定のコツ、そして分析結果の読み解き方と、結果を踏まえて何をやるべきかを考える枠組みといったスキルのほうが相対的に重要になってきているのではないでしょうか。
本書が目指すのは、まさにそうした今こそ必要な「統計学の活かし方」を、物語を通して皆さんにお伝えすることです。たとえば『SLAM DUNK』というマンガを読むことでバスケットボールをプレイするモチベーションが喚起されたり、バスケットボールの観方がわかるようになったりといった方がたくさんいるように、すばらしいマンガは多くの人の人生を変える力を持っています。ありがたいことに私にとっても大好きな漫画家であるうめさん(小沢高広さんと妹尾朝子さん)に漫画制作を依頼できたことで、ストーリー面でも作画面でもすばらしいものになりました。私自身のデータ活用に関わる経験を凝縮した物語を、うまく追体験していただければ幸いです。
また各話の最後には、それまでに出てきた統計手法について、できる限りわかりやすく、かつ簡潔に説明した解説を加えました。ストーリー内ではあまり説明臭くならないよう、しかし気になるであろう知識面はその後の解説で補足できるよう個人的にバランスをとったつもりです。
本書をきっかけに、さらに多くの人が統計学を学び、「新たに何をするか考えて決める仕事」をする力を手にしていただければ幸いです。