『独学大全──絶対に「学ぶこと」をあきらめたくない人のための55の技法』著者の読書猿さんが、「調べものの師匠」と呼ぶのが、元国会図書館司書の小林昌樹さんだ。同館でレファレンス業務を担当していた小林さんが、そのノウハウをまとめた『調べる技術 国会図書館秘伝のレファレンス・チップス』は、刊行直後から反響を呼び、ネット書店ではしばらく品切れ状態が続いた。今回は、連休特別編。二人の対談を3本立てでお届けする。前回記事はこちら。(取材・構成/弥富文次)
 Photo: Adobe Stock
Photo: Adobe Stock
事典としてのChatGPTはどこまで使えるのか
――最近、AIチャットボットの「ChatGPT」が巷でかなり話題になっていますよね。チャットで質問を投げれば、AIが自然言語で答えを返してくれるというものです。「検索する」という行動を消し去るようにも思われる衝撃的なツールですが、読書猿さんはChatGPTによって調べものがどう変わると思われますか?
読書猿:実は、検索スキルというか、その根っこにある考え方って、ChatGPTのようなLLM(注1)をうまく使ってより良い答えを得るのに、めちゃくちゃ使えるんです。もっといえば、広い意味での人文知、〈知識はどのような言葉で書かれてきたか〉についての知識があればあるほど、ChatGPTは使いこなせる。
その理由は、LLMが大量の人間の書き言葉を学習しているから。一般的な取りかけをするとネット全体から学習した結果をもとに一般的な答えが返ってくるんですが、「優秀な編集者として振る舞ってください」のような指示を与えて、解答の元になる「領域」をうまく限定してやれると、ある程度専門的な、あるいは尖った答えが得られる。
以前から、機械翻訳を使いこなせる人って、自分で翻訳できて機械翻訳のミスや弱点がどこか理解できる人だったけれど、それと同じことが当てはまるとも言える。つまり「検索が消える」というより、検索スキルの根っこを理解できる人は、ChatGPTを使いこなせる。そういう意味で、デキる人がより得するツールですね。
日本では、例えばAIは東大に受からない、みたいな本がベストセラーになったりして、「AIは賢くならない」というメッセージが流布され消費されてきました。その間に、世界では、研究が進むだけでなく、大量のデータを学習させるために膨大な資金と計算資源と時間がかけられていて、大半の人間よりも流暢に言葉を扱うLLMが登場した。それも、研究者やプログラマだけが使えるものではなく、言葉を使って対話したり、仕事を頼むといった、僕らが日常的に使ってるインターフェイスを通じて利用できるものとして。
「言葉の使い方」を工夫することで、うまくいったりいかなかったりするのがおもしろくて、ChatGPTは、サービスが出た当初から遊んでいました。たとえば、「5歳の子どもにも分かるように説明してください」という設定をつけてGPSについて尋ねてみたり。
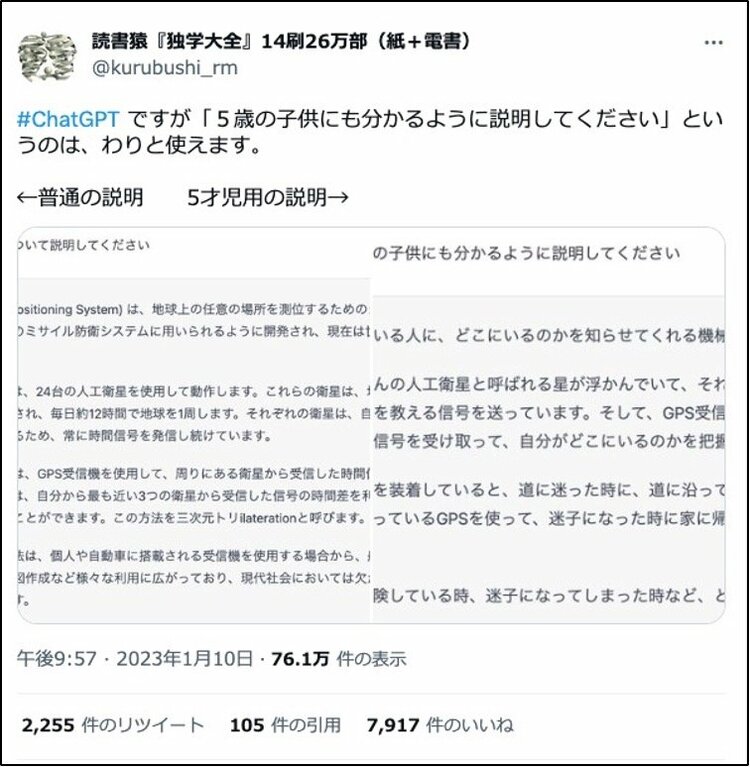
読書猿:ただ、しばらく触っていると、ChatGPTの出力は、そのまま探しものや研究に使えるわけではない、ということが分かってきた。
このAIチャットが学習しているデータは基本的にオープンアクセスなもので、インターネットで誰もが見れる範囲のものです。書籍や有料データベースのデータは当然含まれてない。インターネットにある「書き言葉」でも、質問の後に正しい答えが続くことが多いので、我々の質問に真っ当な答えを返してくれることが多いんですけど、インターネットには当然、事実と一致しない「間違い」もある。明らかな嘘やデマだけでなく、古くなって現状とは食い違ったデータ、間違って信じられている俗説、意図的に事実とは異なることを目指したフィクションもジョークもある。こうしたものも学習データに含まれるので、データを増やしさえすれば、間違いをなくせるわけではない。
ただ「ChatGPTは嘘つきだ」というよりも、騙されてしまう人間側に原因がある気がします。
相手が話す言葉の流暢さで相手の知的レベルを自動的に判定し、さらにそれを発言内容の信憑性の判断にまで反映させる、という重大な脆弱性が、僕らにはあるんです。なので「フェイクニュースについての参考文献を教えて」と質問して、すらすら答えてくれると、「めっちゃ有能!」と感動して、並んだ文献が当然実在するものと思ってしまう。"The Oxford Handbook of the Digital Media and Society" だなんて、いかにもありそうでしょ? ところが"The Oxford Handbook of Digital Technology and Society"や"The Oxford Handbook of Digital Media Sociology"という文献は実在するけど、この文献はないんです(注2)。
こんな風に、出てきた結果を自分で調べて裏付けを取るのは必須です。そういう意味では、何でも答えてくれる、常に正解に導いてくれる、解答マシンではない。ただ本当のことをいえば、書籍だろうが学術論文だろうが、裏を取る必要は常にあるんです。
何かを調べることは、そういう意味で確かに面倒です。だからこそ「すごいAIが探しものなんて面倒事から私達を解放してくれたら」という願いが「万能解答マシン」を求めてしまう。つまりChatGPTについつい事典的な機能を期待してしまうのだけど、嘘をつかまされてがっかりしてしまう。ただ、それだとせっかくのChatGPTのよさを活かせなくて、もったいない気がします。
アイデアを作るのにChatGPTが使える理由
読書猿:考えてみると、「嘘をつけるAIができた」というのは画期的です。デタラメな出力なら簡単ですが、それが無意味なことはすぐに分かるし誰も騙されない。これに対して「嘘」というのは、一見「正しい」と思わせるレベルでないと成立しないわけですから。
この点をどう捉えるかで、ChatGPTをうまく使えるかどうかの明暗が分かれると思います。つまり「何でも答えを出してくれる事典だ」と捉えるのではなく、「正解に縛られず、しかし通用するレベルの何かを生成する機械だ」と考えてみる。
例えば、最近になってよく言われてきていますが、ChatGPTはアイデアを生み出す上で非常に有用です。アイデア出しって、人間がやると結構メンタルに来るんです。なぜなら、アイデアには正解がないから。あらかじめ用意された正解と照らし合わせて〈正しい〉といえるなら、それは新しい考え(アイデア)ではない。キャッチコピーであれば、商品がヒットすればそれが正解だったと、事後的に確かめられるよりほかありません。
間違ってない、これでいいんだという「保証」があればどんどん進めますが、そういう価値評価が定まらない宙吊り状態のまま、たくさんの考えを出すのは、普通の人間にはしんどい。なので「良いアイデア」を出して、早く終わらせようとする訳ですが、その「良い」は既存の価値観に照らしたものなので、飛び抜けたものになりにくい。
その点、ChatGPTに「『調べる技術』のキャッチコピーを100個考えてください」とオーダーすれば、苦もなく応えてくれる。ChatGPTは「正しくないもの」の出力を、飽きることもへこむこともなく無限に挙げ続けられるので、アイデアづくりへの活用は最適な使い方のひとつといえます。
――「ChatGPTはアイデアづくりに使える」という話、目からウロコです! 具体的にはどんなふうな質問の仕方をしていくと良いでしょうか?
読書猿:AIチャットの良いところは制約をかけた上で回答をきちんと出せる点です。だから例えば「役割を与える」といった使い方はいいですよね。「あなたは一流の編集者です。その観点から、小説の斬新なアイデアを出してください」とか。
また、小説のストーリーがほしい場合、「ストーリーを考えてください」だと回答の精度がややイマイチです。そこで、考えるための枠組みを与えるのが有用です。例えばまず、「起承転結って何ですか」「ブレイク・スナイダー・ビート・シートについて説明してください」などと聞いたり、あるいはもっと単純に「物語の構成にあたってどんなフレームワークを知っていますか」と聞く。そして、その答えをもらってから「ではその方法でストーリーを考えてください」と進める使い方もいい。
我々は普段、言葉を投げかけて指示したり質問したりして反応を得て、さらに踏み込んだ指示や質問をするといった風に仕事をしています。ChatGPTは、この人間の仕事のやり方に近い方法でオーダーでき、フィードバックも自然言語で行えるというインターフェイスが良かったと思います。
テクノロジーは知的格差を民主化するのか?
小林昌樹(以下、小林):私はChatGPTにあまり触れていなかったのですが、「嘘ごとを並べ立てるところが強み」という捉え方はなるほどと思いました。GoogleやWikipediaみたいに、ある種の正解を聞くのがありがちな使い方になっているが。ChatGPTは使い手の素養が問われますね。
読書猿:僕が思うChatGPTのすごさを学問の観点から説明するとき、17世紀のイギリスの哲学者フランシス・ベーコンの考え方が使えそうです。ベーコンは、人間の知を「想像」「記憶」「理性」の3つに分けました。分野で言えば「想像」は文学などのエリアで、「記憶」は歴史学など、そして「理性」は哲学や数学が当てはまります。
ベーコンはこれらを並列に考えていますが、僕はそれを縦に積んでみたらどうかと思いついたんです。つまり人間の知においては、最下層の1層目に「想像」があり、2層目に「記憶」、最後の3層目に「理性」があると考える。
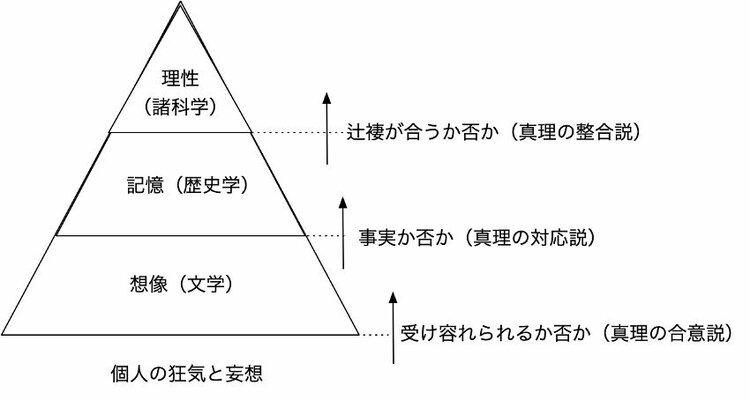
そこで、ある知識が1層目の「想像」から2層目の「記憶」に昇格するときは、どういう場合か。これは「事実か否か」で判断されると言えます。歴史学では、事実と認められたために記憶の領域に移行する。妄想は切られてしまい、「記憶」の層には移らないわけです。
次に、2層目の「記憶」から3層目の「理性」への昇格ではどうか。これは、整合性があるかどうかで判断されるといえます。数学の命題は、数学の中での整合性があれば認められる、といった視点です。
このように、2層目「記憶」や3層目「理性」の知を生み出す方法論は学問の中で確立されてきました。しかし、1層目の「想像」を生み出すのはこれまで人間個人の主観でしかなかった。でも「想像」を補えるのが機械としてのChatGPTなんです。こう捉えると、ChatGPTを「ものすごい文房具」と見る意図が伝わるのではないでしょうか。
小林:面白いです。どんな分野でも良いのですが、ChatGPTも既に知識の枠組みを持っている専門家にとっては、効率化を促進する便利なツールになるはずです。一方で、知的格差を拡大するようなツールにもなり得ると思います。
読書猿:まさにそうですね。テクノロジーは知的格差を民主化すると言いながら、このツールは格差を生み出す可能性が高いです。ChatGPTはいわば知識の拡大鏡。1や2を拡大すれば、10や20になると思いますが、0は拡大しても0のままです。勉強して知識を持っている人にとっては、それを拡大していける鏡のような気がする。だから自分の頭で勉強するという重要性はなくならないと思います。
元国立国会図書館司書、『調べる技術』著者
1967年東京生まれ。1992年慶應義塾大学文学部卒業。同年国立国会図書館入館。2005年からレファレンス業務に従事。2021年退官し慶應義塾大学でレファレンスサービス論を講じる傍ら、近代出版研究所を設立して同所長。2022年同研究所から年刊研究誌『近代出版研究』を創刊。専門は図書館史、近代出版史、読書史。
編著に『雑誌新聞発行部数事典: 昭和戦前期』(金沢文圃閣、2011)などがある。『公共図書館の冒険』(みすず書房、2018)では第二章「図書館ではどんな本が読めて、そして読めなかったのか」を担当した。
★『独学大全』公式Twitterはこちら
読書猿(どくしょざる)
ブログ「読書猿 Classic: between/beyond readers」主宰。「読書猿」を名乗っているが、幼い頃から読書が大の苦手で、本を読んでも集中が切れるまでに20分かからず、1冊を読み終えるのに5年くらいかかっていた。
自分自身の苦手克服と学びの共有を兼ねて、1997年からインターネットでの発信(メルマガ)を開始。2008年にブログ「読書猿Classic」を開設。ギリシア時代の古典から最新の論文、個人のTwitterの投稿まで、先人たちが残してきたありとあらゆる知を「独学者の道具箱」「語学の道具箱」「探しものの道具箱」などカテゴリごとにまとめ、独自の視点で紹介し、人気を博す。現在も昼間はいち組織人として働きながら、朝夕の通勤時間と土日を利用して独学に励んでいる。
『アイデア大全』『問題解決大全』(共にフォレスト出版)はロングセラーとなっており、主婦から学生、学者まで幅広い層から支持を得ている。本書は3冊目にして著者の真骨頂である「独学」をテーマにした主著。なお、「大全」のタイトルはトマス・アクィナスの『神学大全』(Summa Theologiae)のように、当該分野の知識全体を注釈し、総合的に組織した上で、初学者が学ぶことができる書物となることを願ってつけたもの。
ブログ
https://readingmonkey.blog.fc2.com/
ツイッター
https://twitter.com/kurubushi_rm

一生使えて今日から役立つ! 3つの工夫
【工夫①】「無知くんと親父さんの対話」でざっくり概要をつかめる
本書は独学者の手元に置かれ、悩んだときに必要な箇所(技法)を読めるつくりになっています。さらに「ざっと読んで概要を把握したい」「独学の結果を早く出したい」という方向けに、章の冒頭には「無知くんと親父さんの対話」がついています。これを15章分読むだけで、一番大事なポイントは読了できます。
【工夫②】「なぜ学ぶのか」「何を学ぶのか」「どう学ぶのか」を3部構成で完全網羅
既に勉強の目的が決まっている人は「Howどう学ぶのか」を扱った第3部から。自分が知りたいこと、分野を調べたいなら「What 何を学ぶのか」を扱った第2部から。そして、そもそも「Whyなぜ学ばなければならないのか」に立ち返るときは第1部から。あなたのゴールに合わせて深堀りできるつくりになっています。
【工夫③】あらゆる独学の土台になる「国語」「英語」「数学」の学び方も掲載
独学をする上で3つの言語「国語」「英語」「数学」(本書では、数学も言語のひとつと捉えています)がわかると、自分が扱える本や論文、ネットの情報などの幅がいっきに広がります。第4部では、この3つを学ぶときに大切な「骨法」と、「ある独学者」のケーススタディを掲載。1~55の技法をどう使えばよいかがわかります。








