統計学の解説書ながら42万部超えの異例のロングセラーとなっている『統計学が最強の学問である』。そのメッセージと知見の重要性は、統計学に支えられるAIが広く使われるようになった今、さらに増しています。そしてこのたび、ついに同書をベースにした『マンガ 統計学が最強の学問である』が発売されました。本連載は、その刊行を記念して『統計学が最強の学問である』の本文を公開するものです。第32回では、「エビデンス」についての基礎知識を解説します。(本記事は2013年に発行された『統計学が最強の学問である』を一部改変し公開しています。)
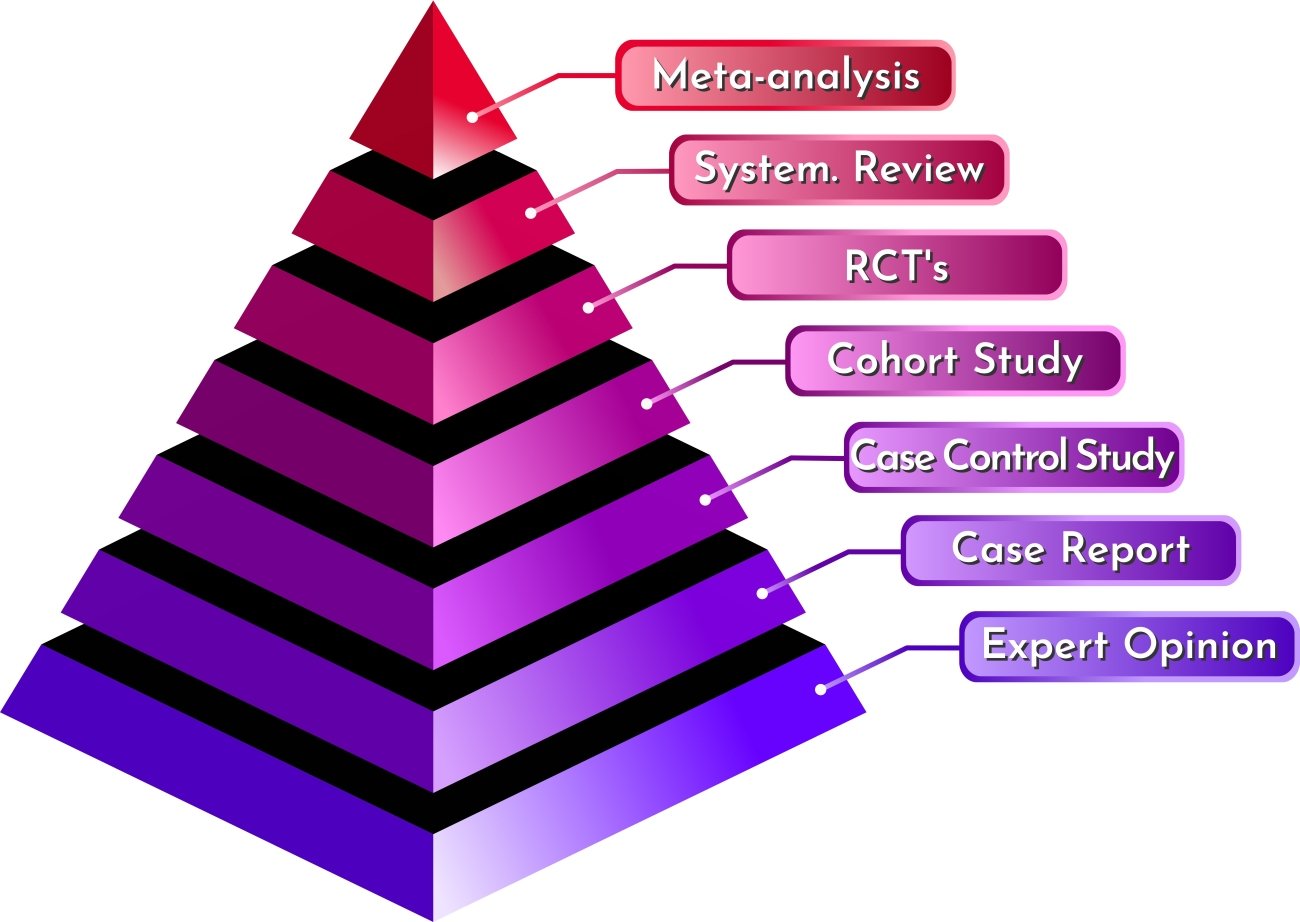 Photo: Adobe Stock
Photo: Adobe Stock
「最善の答え」を探せ
ここまでに書いた内容を十分身につけていれば、統計学で記述されたほとんどの情報について、その意味や限界についてよく理解できるはずである。
近代物理学を生み出したアイザック・ニュートンは「私が遠くを見ることができているのだとすれば、それは巨人の肩に立っていたからです」という言葉を残している。巨人とはすなわち「先人たちの知恵」という意味だ。先人たちの積み重ねた知恵をきちんと学び、その上に立脚することができれば自分だけの頭を絞るよりも遥かに先を見通せるはずである。ニュートンという大天才ですらそうしているのに、なぜ我々がそうせずにいられるのだろう。
世界中には学者や専門家が生涯をかけて明らかにしたさまざまな知恵がある。それはこれまでにも何度か紹介した事実であるが、現代においてその知恵の多くは回帰係数やp値といったものによって表現されている。統計リテラシーはこうした知恵を迅速かつ正確に活用できるように、ひいてはあなたを巨人の肩に導いてくれるはずだ。
本書の終章として、統計リテラシーを実際にあなたの人生に活かすためのエビデンスの探し方について紹介したい。
エビデンスのヒエラルキー
第3回でも述べたように、エビデンスとは科学的な根拠のことだ。現代の医療はEBM(Evidence-Based Medicine)と呼ばれ、必ずエビデンスに基づいた治療を選択しなければいけないということになっているし、前に述べたように欧米では教育や政策決定においてもエビデンスが重視されるべきであるという法律・ガイドラインが増えてもいる。
科学的根拠というと、科学的に研究された結果は何でもエビデンス扱いするのかということになってしまうが、エビデンスはすべて横並びのものではない。ほぼ間違いない根拠として信頼すべきものから、参考程度の仮説レベルまでのヒエラルキーが存在しているのだ。
その一番最下層に属するエビデンスは「専門家の意見」と「基礎実験の結果」である。
専門家の意見がエビデンスとして最低限の信頼性しかないというのは今更書くまでもないと思う。一方基礎実験とは、試験管の中で行なった生化学的な実験や、ネズミやサルなどを使った動物実験などのことである。
ちなみに個人的に今まで聞いたエビデンスの中で一番微妙な気持ちになったものに、「卵がうつ病に効く」という「エビデンス」がある。うつ病に関わる動物実験としてよく行なわれるものの1つに、「ネズミを水槽で溺れさせる」というものがあり、ネズミが一定時間足掻いたあとに無力感にさいなまれて動かなくなっている状態は、人間のうつ病とほぼ同様のものだと考えられるらしい。そして1か月間卵を食べさせられたネズミは、そうでないネズミの1.3倍の時間、足掻き続けたというのである。
動物実験の倫理的にどうこうというところも気にならなくはないが、溺れ死ぬ直前のネズミの諦めと人間のうつ病の治療を同じように考えるという推論に、疑問を持つ人はおそらく少なくないはずだ。
こうした動物実験での結果以外にも、「脳の中で◯△という働きをしている成分だから」とか、「体の中で◯□を作っている成分だから」とかいう根拠しかないのに、「この栄養素を食べることが体にいい」という言説が、なぜかテレビにも雑誌にもあふれている。しかしながら、髪の毛を食べたからといってハゲが治らないのと同様、体の中で何らかの働きをしている成分をそのまま食べて効果があることは少ない。胃や腸で分解されたり、肝臓や腎臓で代謝されたりするわけであるし、脳に繋がる血管には不要な物質が流れないよう血液脳関門という機構が働いている。
だからこそ製薬会社は、基礎実験の結果を商品化させるために何百億円というレベルの莫大な研究費を費やして、何とか標的とする臓器に届くようにするためにはどのような化学構造と投与方法にすればよいか、そしてどうすれば人間に対して危険なく有効性を発揮できるかを調べる。こうした研究を経ると、実際のところ基礎実験の成果の多くは最終的なランダム化比較実験にたどり着くこともなくボツになる。
こうした過程をすっとばして、基礎実験の結果だけから「体にいい」「脳にいい」と安直に考えるのはあまりにも人体や薬学、さらには基礎実験の研究自体をナメすぎた飛躍である。基礎実験はその積み重ねによって実証すべき重要な仮説を生み出してくれるが、そのまま人間や社会に適用できるほど科学は単純なものではないのだ。
最高のエビデンス「系統的レビュー」と「メタアナリシス」
ではどのようなエビデンスがよいのだろうか?
こと人間に応用すべきエビデンスとして重要視されるのは、「実際に現実的なシチュエーションで、ある程度の数の人間を分析した結果」である。こうした研究の方法として、みなさんはすでに疫学などの観察研究とランダム化比較実験があるということをご存じのはずだ。そして、ランダム化比較実験によって示された結果は、ある一点を除いてほぼ間違いなく信用できる「妥当な因果推論」だということも学んだはずである。
ランダム化比較実験において唯一残された課題は、研究の対象となった人間が大抵の場合、全国民や全人類から選ばれたランダムサンプリングなどではない、ということである。大学生だけとか、医者だけとか、70歳以上の老人だけといった限られた集団の中では確かに妥当な推論ができたとしても、「他ではどうなのか」という批判をかわしきることはできない。
そこで行なわれるのが、系統的レビュー(systematic review)とメタアナリシス(meta-analysis)である。
レビューとは複数の研究をまとめて結局のところ何が言えるのかを述べることである。たとえばビデオゲームと少年犯罪の関連性について興味を持っている学者なら、この領域でこれまでに誰がどのような研究を行ない、その結果どういったことがわかったのかをよく知っているはずだ。そうした情報を整理し、紹介し、そのうえで自説を展開する、という行為は学者がどんな文章を書く際にも必ず行なわなければいけない。
だがこうしたレビューにおいては、自説に都合のよい結果ばかりを示すことも可能である。仮にゲームが少年犯罪に悪影響を持っているという立場で研究をしている学者であれば、自説に都合の悪い「ゲームと少年犯罪の関連性を分析したが誤差の範囲と呼べる程度のものだった」とか、「むしろ少年犯罪が減っていた」という研究を紹介しないことも可能なわけである。
だからこうした「自説に基づくレビュー」は、今では叙述的レビューと呼ばれて、その主観性に注意が払われるようになった。一方で、より客観的な系統的レビューが重要視されているのである。
系統的レビューはあらかじめ「レビューする論文の条件」を決めたうえで、過去に公表された関連分野の文献すべてから条件に該当するものを選び出す。先ほどの例で言えば、「未成年 犯罪 ビデオゲーム」という単語を含み、少年犯罪とビデオゲームとの関連性について何らかの統計解析が行なわれた論文すべてを収集・分析し、その結果どういうことがわかるかという結論をまとめるのである。これはほとんど主観などが含まれない「現時点で最善の答え」となるはずだ。
なお、メタアナリシスとは、こうした系統的レビューの中で、複数のランダム化比較実験や観察研究の中で報告された統計解析の結果を、さらに解析してまとめあげる作業のことをいう。「解析(analysis)に対する解析(analysis)」だからメタアナリシスというわけである。
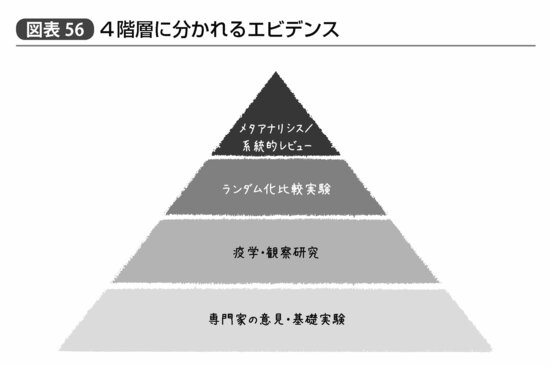
系統的レビューとメタアナリシスを頂点として、エビデンスのヒエラルキーは図表56のように整理される。専門家の意見や基礎実験よりも観察研究のほうが、そしてさらにランダム化比較実験のほうが信頼すべきエビデンスであり、複数のランダム化比較実験や観察研究をメタアナリシスして得られた結果は今のところ最善の答えだ、というのである。
「最善の答え」は公開されている
系統的レビューとメタアナリシスの結果は、人類全体で共有すべき「最善の答え」であるから、さまざまな分野でその結果を集めて共有しようという取り組みがなされている。
こうした取り組みのうち最初に行なわれたのは、イギリスの医師であり疫学者であるアーチボルト・コクランの提唱により、1992年にイギリスで始まったコクラン共同計画がある。またコクラン共同計画に影響され、社会政策科学分野においてはキャンベル共同計画が2000年にスタートしているし、2002年にスタートした教育学分野のWhat Works Clearinghouseプロジェクトについても第3回で紹介した。
彼らはウェブサイト上で系統的レビューの結果を公表しているので便利だが、それ以外の一般的な論文データベースの中で、キーワードに「meta-analysis or “systematic review”」と含む検索を行なうというやり方もある。以下にいくつか代表的な英語の文献データベースを紹介するので参考にしてほしい(なお大学や大きな図書館の司書さんに聞けばこれより詳しく教えてもらえるかもしれない)。
また、Googleの提供するGoogle Scholarも便利な文献検索サービスである。英語だけでなく日本語の文献を探すこともできるし、Google的な「重要度の高い文献ほど上位に」といった機能も実装されているようだ。

これらはすべて基本的に英語で書かれたものであるが、英語がまったく読めない人もエビデンスに触れることはできる。日本語で操作できる日本語文献の文献データベースとしては、国立情報学研究所によるciniiと、科学技術振興機構が運営するJ-STAGEが代表格であり、ここから検索すればたいていの日本語で書かれた論文は探すことができる。英語だったらいくらでも見つかるような研究が日本語の論文ではまったく見つからない、という検索結果を見て日本人研究者の怠慢や勉強不足に憤ってみるのもいいかもしれない。
ちなみに英語が苦手な人であったとしても、統計リテラシーさえあれば結果の解釈だけならばそれほど問題がなかったりもする。
私自身、それほど英語が得意でなかった学生時代でも文献の結果が読み取れていたのは、多くの結果は文章ではなく表の形で示されており、重要な中身は数字で書かれているからだ。あとはregression coefficient(回帰係数)とかconfidence limit(信頼限界あるいは信頼区間)とかp-value(p値)とかsignificant(有意つまり誤差の範囲でないこと)といった基本的な統計学英語を理解して、説明変数や結果変数の意味だけを何とか辞書で調べれば、おおよそ何を言わんとしているかわかるようになってくるのである。
▶『マンガ 統計学が最強の学問である』の刊行に寄せて
『マンガ統計学が最強の学問である』は、言語化・定型化された仕事がAIに奪われていくなかで、「新たに何をするか考えて決める」スキルを日本に最大限広げるために制作されました。
実は初代『統計学が最強の学問である』はほとんど数式を使わず、統計学がどう生まれてどう役に立てられるのかにフォーカスした、統計学の本としては少し変わった本でした。しかし、40万部以上売れただけあって、あの本を読んで統計学を面白いと感じ、本格的に勉強しようとしたり、実務に活かすようになった、という方と私は日々の仕事の場で頻繁にお会いします。統計手法の数理面を細かく説明したり、統計解析をおこなうためのプログラミングに関する本は多数ありますが、それはちょうどAIのサポートが手厚くなっている部分です。今の時代はそれよりも、「統計学を活用したい」というモチベーション、「どのような課題に対して統計学を活用するか」という課題設定のコツ、そして分析結果の読み解き方と、結果を踏まえて何をやるべきかを考える枠組みといったスキルのほうが相対的に重要になってきているのではないでしょうか。
本書が目指すのは、まさにそうした今こそ必要な「統計学の活かし方」を、物語を通して皆さんにお伝えすることです。たとえば『SLAM DUNK』というマンガを読むことでバスケットボールをプレイするモチベーションが喚起されたり、バスケットボールの観方がわかるようになったりといった方がたくさんいるように、すばらしいマンガは多くの人の人生を変える力を持っています。ありがたいことに私にとっても大好きな漫画家であるうめさん(小沢高広さんと妹尾朝子さん)に漫画制作を依頼できたことで、ストーリー面でも作画面でもすばらしいものになりました。私自身のデータ活用に関わる経験を凝縮した物語を、うまく追体験していただければ幸いです。
また各話の最後には、それまでに出てきた統計手法について、できる限りわかりやすく、かつ簡潔に説明した解説を加えました。ストーリー内ではあまり説明臭くならないよう、しかし気になるであろう知識面はその後の解説で補足できるよう個人的にバランスをとったつもりです。
本書をきっかけに、さらに多くの人が統計学を学び、「新たに何をするか考えて決める仕事」をする力を手にしていただければ幸いです。







