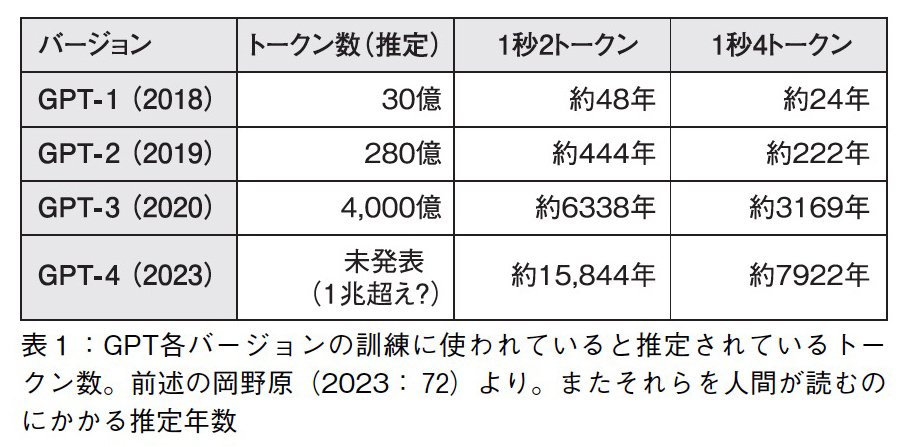
ここで、1秒に2単語読むと仮定すると、GPT-3やGPT-4の訓練データ量は、人間が24時間寝食を犠牲にして読み続けても、それぞれ約6300年、1万5000年以上かかる量です。1秒に4単語読めると仮定しても、この値は半分にしかなりませんから、やはり膨大な時間がかかることがわかります。
表1に、GPTのそれぞれのバージョンに使われたトークン数と、それを人間が読むのに必要な推定年数をまとめました。
 同書より転載
同書より転載
これだけ莫大な量の訓練データを必要とするのが、今の生成AIなのです。もちろん、人間だって、読み聞かせや語りかけをたくさん受けるほど、言語能力が豊かになることは間違いありません。
ですが、赤ちゃんが基礎的な言語知識を獲得するプロセスは、たった数年で達成されるのです。そう考えると、生成AIが人間と同じ「言語」を扱っているように見えても、その背景にある学習の仕組みは、まったく別のものであると結論づけられます。
人間の子どもは、母語を獲得するのに4000億単語も必要としません。ですから私も妻も、生成AIの言葉を「それっぽく見えるけれど、根っこは別物」として捉えた方が、子どもの言語環境を考える上では健全ではないか、と感じています。
なぜ生成AIの言葉は
「それっぽく」聞こえるのか?
ひと言でまとめると、生成AIと人間言語は、その学習に使用するデータの「質」も「量」もまったく異なるのです。「じゃあ、なんで現在の生成AIは、まるで人間が話すかのように話せるの?」という疑問が飛んできそうです。ひと言で答えるとすると「なんでだかは、よくわからない」なのですが、もう少し詳しくお話ししましょう。








