「なぜデマは真実よりも速く、広く、力強く伝わるのか?」SNSに潜むウソ拡散のメカニズムを、世界規模のリサーチと科学的研究によって解き明かした全米話題の1冊『デマの影響力──なぜデマは真実よりも速く、広く、力強く伝わるのか?』がついに日本に上陸した。ジョナ・バーガー(ペンシルベニア大学ウォートン校教授)「スパイ小説のようでもあり、サイエンス・スリラーのようでもある」、マリア・レッサ(ニュースサイト「ラップラー」共同創業者、2021年ノーベル平和賞受賞)「ソーシャル・メディアの背後にある経済原理、テクノロジー、行動心理が見事に解き明かされるので、読んでいて息を呑む思いがする」と絶賛された本書から一部を抜粋して紹介する。
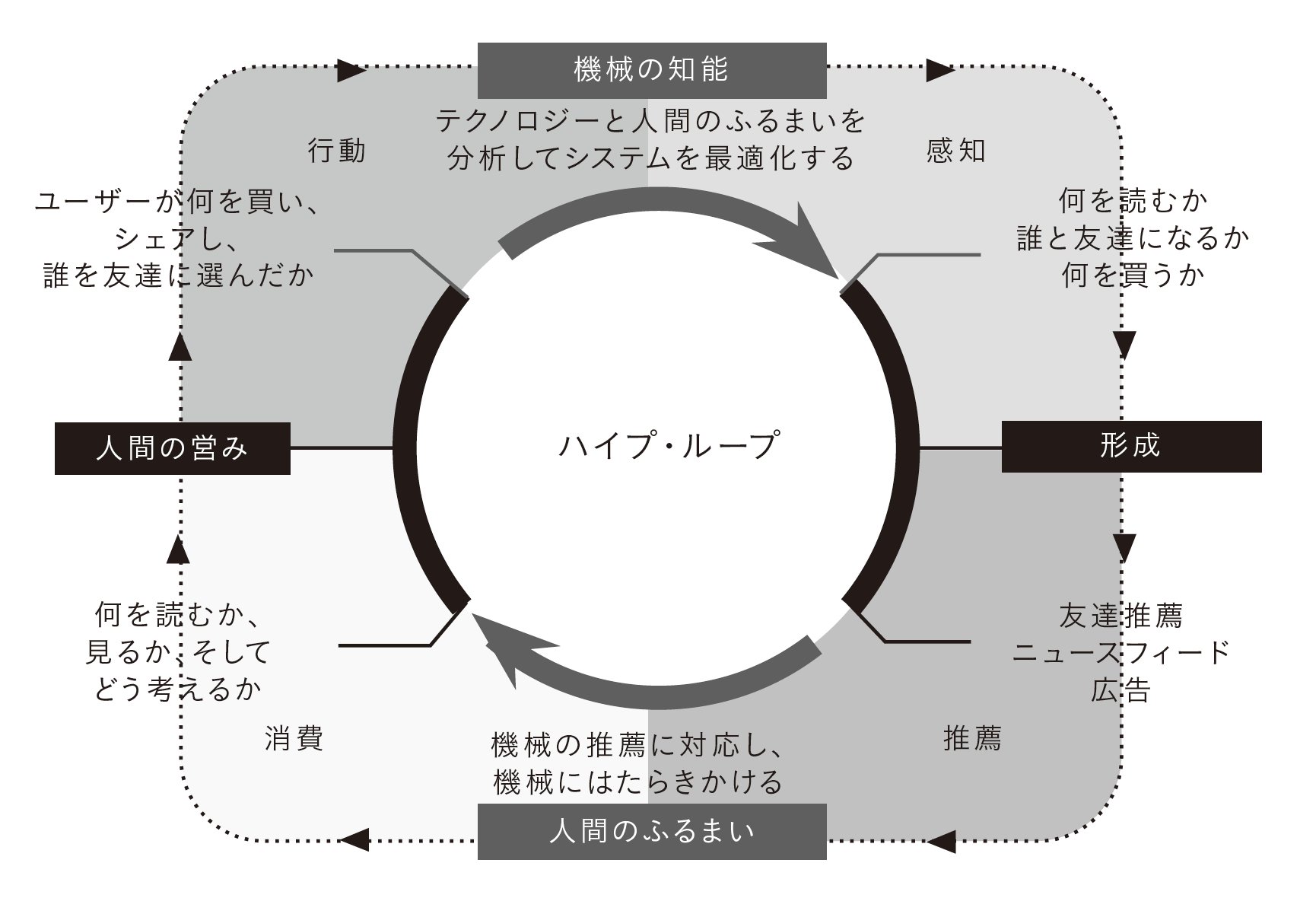 「ハイプ・ループ」の図。機械の知能と人間の行動の相互作用。機械の知能は、人間の行動を感知し、その分析に基づいて情報を推薦する。つまり、機械の知能は人間の選択の幅を狭める。人間は機械の推薦に対応して、選択し、またその選択が機械の知能に影響を与える。
「ハイプ・ループ」の図。機械の知能と人間の行動の相互作用。機械の知能は、人間の行動を感知し、その分析に基づいて情報を推薦する。つまり、機械の知能は人間の選択の幅を狭める。人間は機械の推薦に対応して、選択し、またその選択が機械の知能に影響を与える。
ネットの「ぐにゃぐにゃ文字認証」知られざる役割
私のMITの元同僚、イヤッド・ラーワン、ピナール・ヤナルダグ、マニュエル・セブリアンは最近の研究で、人間の営みが機械にどう影響するのか、その典型的な例を提示した。
イヤッドは、ハイプ・マシンに組み込まれた知能が、入力されたデータにどう影響されるのかを知ろうとした。つまり、ソーシャル・メディアのアルゴリズムが、データによって私たちのふるまいについて学んだ時、どのように「考え方」を変えるのかを知ろうとしたわけだ。
MITのチームが特に力を入れたのは「自動イメージ・ラベリング」の分析である。これは、ソーシャル・メディアでも、ウェブでも、機械の知能が一般的に行なう操作だ。
「キャプチャ(Completely Automated Public Turing test to tell Computers and Humans Apart=CAPTCHA)」というテストは、おそらくほとんどの読者が受けたことがあるだろう。
これは、カーネギーメロン大学の私の同僚、ルイス・フォン・アンが発明したテストだ。歪んだ文字や数字の画像を読み取れるかを見て、応答者が人間なのかコンピュータなのかを見分けるテストだが、歪んだ文字や数字を読み取るのは人間でもかなり困難で、いらだつことも多い。
テストのアルゴリズムは、入力結果を基に自動的に学習し、それを次回以降の文字や数字の提示に活かす。
このテストには重要な目的がある。テストに利用された画像には毎回ラベル付けが行なわれ、そのラベルが、毎日ソーシャル・メディアに何千億と投稿される画像の分類、保存、検索、説明などに利用されるのだ。
AI「ノーマン」の開発
イヤッドのチームは、投稿された画像が無害で多くの人が好感を持つものである場合と、不快で有害なものである場合とで、イメージ・ラベリング・アルゴリズムの反応がどう変わるかを知ろうとした。
そのために、ソーシャル・メディア上の画像にキャプション(説明)をつける人工知能(AI)のディープ・ラーニング・アルゴリズムを作った(1)。
このAIは、アルフレッド・ヒッチコックの1960年代の映画「サイコ」でアンソニー・パーキンスが演じた登場人物(ノーマン・ベイツ)にちなんで「ノーマン」と名づけられた。絶えず猟奇的な画像を供給しつづければ、アルゴリズムがノーマンのように猟奇的な性格になるか否かを確かめようとしたからだ。
ユーザーの投稿によって、ハイプ・マシンの思考、少なくともそれを構成するアルゴリズムの思考は変化するのか、するとしたらどう変化するのかを確かめたかったのだ。



