生成AIが一変させる
企業のデータ戦略
2010年前後に「ビッグデータ」という言葉が流行したこともあり、多くの企業はデータはいずれ価値を生むという前提で、様々なデータの収集に乗り出しました。その結果として、具体的な利用目的が決まっていようとなかろうと、「とりあえず」データを収集・保存している企業は少なくありません。ただ、データの収集・保存もコストと手間がかかります。
一方、データを生成AIで合成できるのであれば、データを収集するより合成した方がコスト効率がいいということになります。結果として、これまではビッグデータビジネスにおいてデータを蓄積している企業が有利だったのが、今後は必要なデータを合成できる企業が有利になります。前述した自動運転AIの例でいえば、テスラやグーグルと比較して実走行画像の大量収集に出遅れた日本の自動車メーカーにも、勝ち筋が見えることになります(※1)。
 『2030 次世代AI 日本の勝ち筋』(佐藤一郎 日経BP)
『2030 次世代AI 日本の勝ち筋』(佐藤一郎 日経BP)
一方で企業において生成AIによる合成データが増えれば、データ収集に代わって、生成AIが生み出した大量のデータを学習させて学習モデルを構築する処理に向けた計算能力の確保が、企業の差別化要素になる可能性があります。
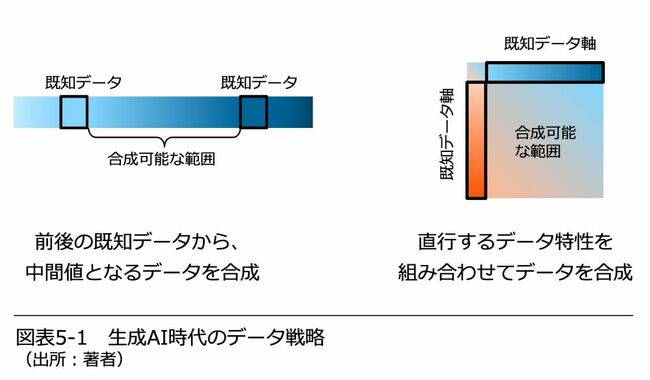
その結果、企業のデータ戦略は大きく変わります。闇雲に実データを集めるのではなく、図表5-1のようにデータ合成に資するデータセットを想定しておいて、そのデータセットを収集して、あとは生成AIによる合成を行うことになります。そのデータ戦略は、イメージ的にはパズルの数独に近いかもしれません。
一部のマス目の数字をあらかじめ与えておくと、残りのマス目の数字が埋められるように、与えておくべき数字に相当するデータセットを見極めて、それをまず集めておいて、残りのデータは生成AIを駆使して合成していくことになるでしょう。
※1 ただ、その日本の自動車メーカーが生成AIによる合成データに積極的に取り組んでいるかは別の問題となります。
 同書から転載
同書から転載







