データがあるのに使えない日本
現在、世界ではデータをどう共有し、いかに信頼できるかたちで活用するかを競う時代に入っている。日本でもEUのデータスペースとの接続実証や、国内独自のデータ共有基盤の整備が進んでいるが、個社レベルでいえば、データの活用は十分に進んでいない。
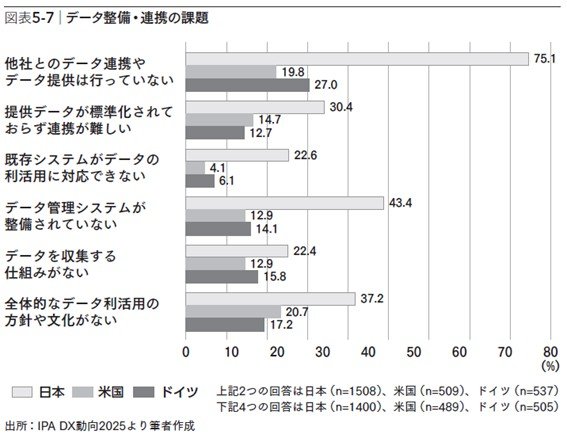
独立行政法人情報処理推進機構の調査において、他国と比較し、「他社とのデータ連携やデータ提供は行っていない」という数値が75.1%にのぼっており、データ共有が進んでいない現状がうかがえる。
そもそも、多くの企業ではその前提となる仕組みづくりが整っていない。全社的なデータ活用方針や文化がないと答えた企業が4割近くにのぼり、データ管理システムの未整備を挙げる企業も多い。つまり、日本の課題は、データがあるのに使えないという構造的な段階にある。
データを眠る資源から動く資産に変える
データを資産化するには、まず社内のルールと責任体制を明確にしなければならない。どのデータを、どの目的で利用し、誰が管理責任を負うのかという基本原則を整備し、経営層から現場まで共通の認識を持つことが出発点である。データの利活用を促す文化や評価制度も、この段階で確立する必要がある。方針が曖昧なままでは、現場はリスク回避に傾き、データは閉じたままになる。
次に必要なのは、レガシーシステムの改修とデータ管理基盤の整備である。多くの企業では、既存システムがデータの再利用や外部連携に対応しておらず、フォーマットの不統一や欠損が共有の妨げとなっている。
まずはデータを収集・蓄積しやすい構造に刷新し、管理責任を一元化することで、部門を超えたデータの流通が可能になる。この段階で初めて、データの品質管理やメタデータ整備といった見える化が進む。
その上で、企業は自社データを「オープン化可能データ」「条件付き共有データ」「完全クローズデータ」といったかたちで分類し、共有の設計図を描く段階に入る。データの棚卸しと分類はゴールではなく、ルールと基盤を整えた結果として実現するプロセスである。つまり、データ資産化は棚卸しから始まるのではなく、「ルール策定→基盤→棚卸し」という3層構造で進めるべき課題なのである。
もっとも実務では、この棚卸しの段階に入る前に、そもそも社内の情報が構造化されておらず、担当者の記憶や紙資料、部門ごとのファイル、現場の帳票などに散在しているため、棚卸し作業そのものが進まない企業も少なくない。特に中小企業や現場部門では、データが存在していても、形式がバラバラであること、作業負荷が大きいことなど、難しいことが障壁となり、棚卸しを始められないという状態に陥りやすい。
ここで生成AIの「マルチモーダル統合」が重要になる。マルチモーダル統合とは、データ形式が異なる種類の情報や、画像、音声といった数値化されていないようなデータ(いわゆる非構造データ)でも理解・処理できる技術である。紙の台帳、電子ファイルの帳票、手書き伝票、画像化された書類でも取り込むことができ、棚卸しの初期作業を半自動化できる可能性がある。
完全に正しい台帳を1度でつくることはできないものの、人が確認しながら精度を上げていく継続プロセスとして、棚卸しを立ち上げやすくなる。
生成AIはデータ資産化のプロセスを置き換えるものではない。誤読や欠損は起こりうるため、人による確認やルールの整備は不可欠である。それでも、資産として扱うべきデータを現実に見える化し、棚卸し作業の入り口負担を下げる加速装置となりうる。重要なことは、データを「整備してから使う」から「使いながら整備する」方向に転換し始めたことである。
こうして初めてデータは、眠る資源から動く資産へと変わる。データ共有の基盤が整備される今こそ、日本企業は自社内部の構造的課題を克服し、データを活かす体質へと変革を加速させる必要がある。社内のデータ整備は、日本企業がデータ共有時代の競争に参加するための最低条件という危機感が必要なのである。







