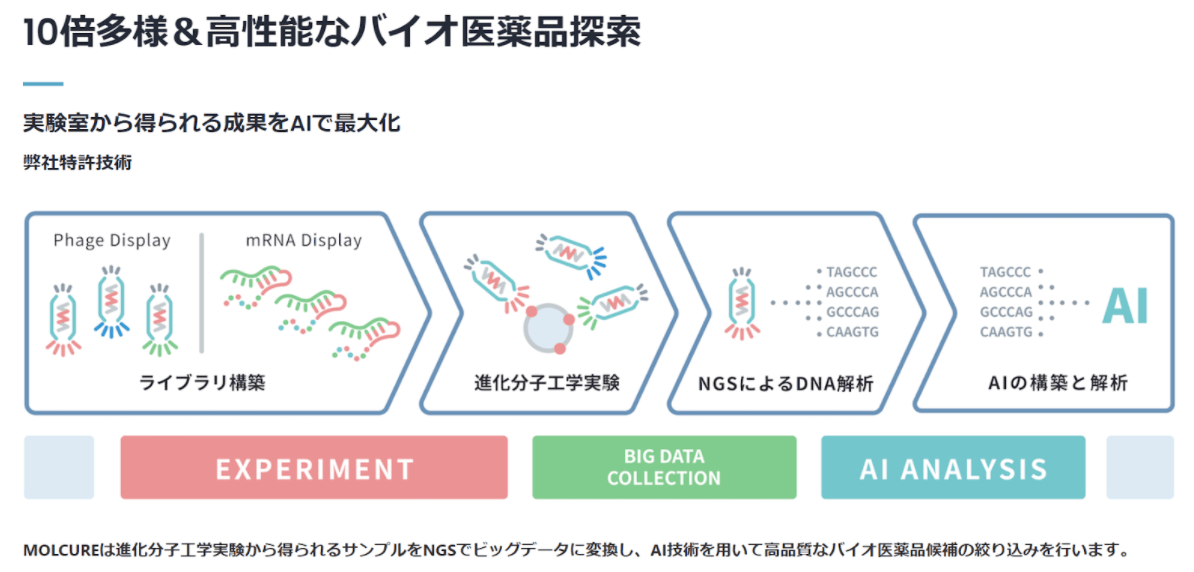
「属人的ではなく、かつセレンディピティ(偶然性)にも頼らないかたちで新たな薬をいくつも生み出せるような仕組みを作れないか。それを考えた結果が(従来の実験ドリブンから)データドリブンへの転換という考え方でした」(小川氏)
ポイントとなるのが教師データだ。優れたAIを作る上では学習データが鍵を握るが、匠の技からデータを抽出すること自体が難しく、1つのボトルネックになっている。結果として十分なデータを集められないため、AIを開発するハードルも高くなるという。
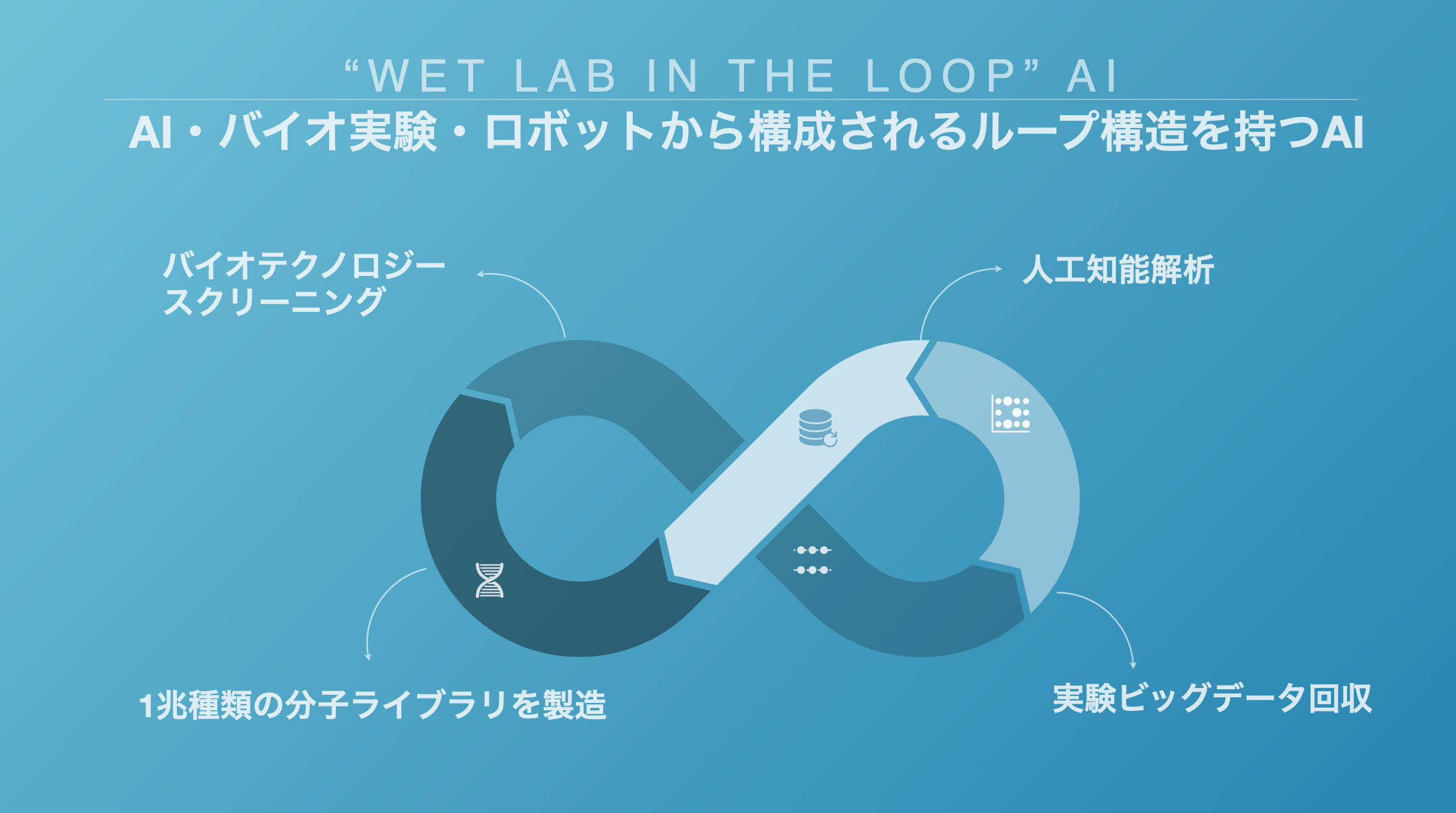
一方でMOLCUREでは上述したように、進化分子工学実験からデータを吸い上げる技術を確立(関連する特許も2つ取得)。その上で実験のプロセスを半自動化するための「ロボット」をわざわざ自社で開発し、データの収集からAIの構築、設計図の生成、その精度の検証に至る一連のループを効率よく何度も回せる体制を作り上げた。
「単純なデータ量で言えば世界最大のパブリックDBでも500万エントリーしかデータがないところ、自分たちは10億エントリー以上のデータを集めている」(小川氏)状態を実現できたのは、この取り組みを約8年間に渡って地道に続けてきたからだ。
「全ての技術がAIを中心に設計されています。最強のAIを作るために、AIフレンドリーなかたちでたくさんデータを集められそうな実験手法は何かを考え、あえて王道ではない進化分子工学実験を選び、ロボットチームも作りました。これについては手段を問わず、ある意味“変質的”にやり込んできました。自分自身でもとち狂ったチームだと思いますし、実際に抗体の実験をやっている方からもそのように言われます」(小川氏)

これまでMOLCUREでは米Twist Bioscienceや日本ケミファをはじめとする大手製薬企業、大手製薬バイオテック企業など、累計7社10プロジェクトに自社技術を提供してきた。
各企業との取り組みを通して「従来の方法と比べた場合に医薬品候補分子の発見サイクルを10分の1以下に効率化できること」、「10倍以上多くの新薬候補を発見できること」、「探索が困難だった、優れた性質を持つ分子の設計が可能になること」などが実例として示せる状態になっているという。
ある製薬企業は匠の技を駆使してバイオテクノロジーの実験で抗がん剤を探索するプロジェクトを進めていたが、1種類のバイオ医薬品候補しか見つけることができず苦戦していた。そこでMOLCUREの技術を用いたところ、14種類の候補を発見することに成功。しかも以前エキスパートが見つけた候補よりも性能面で優れたものをAIが発掘できたことがわかった。



