
データの準備と事前の加工が成功の鍵となる
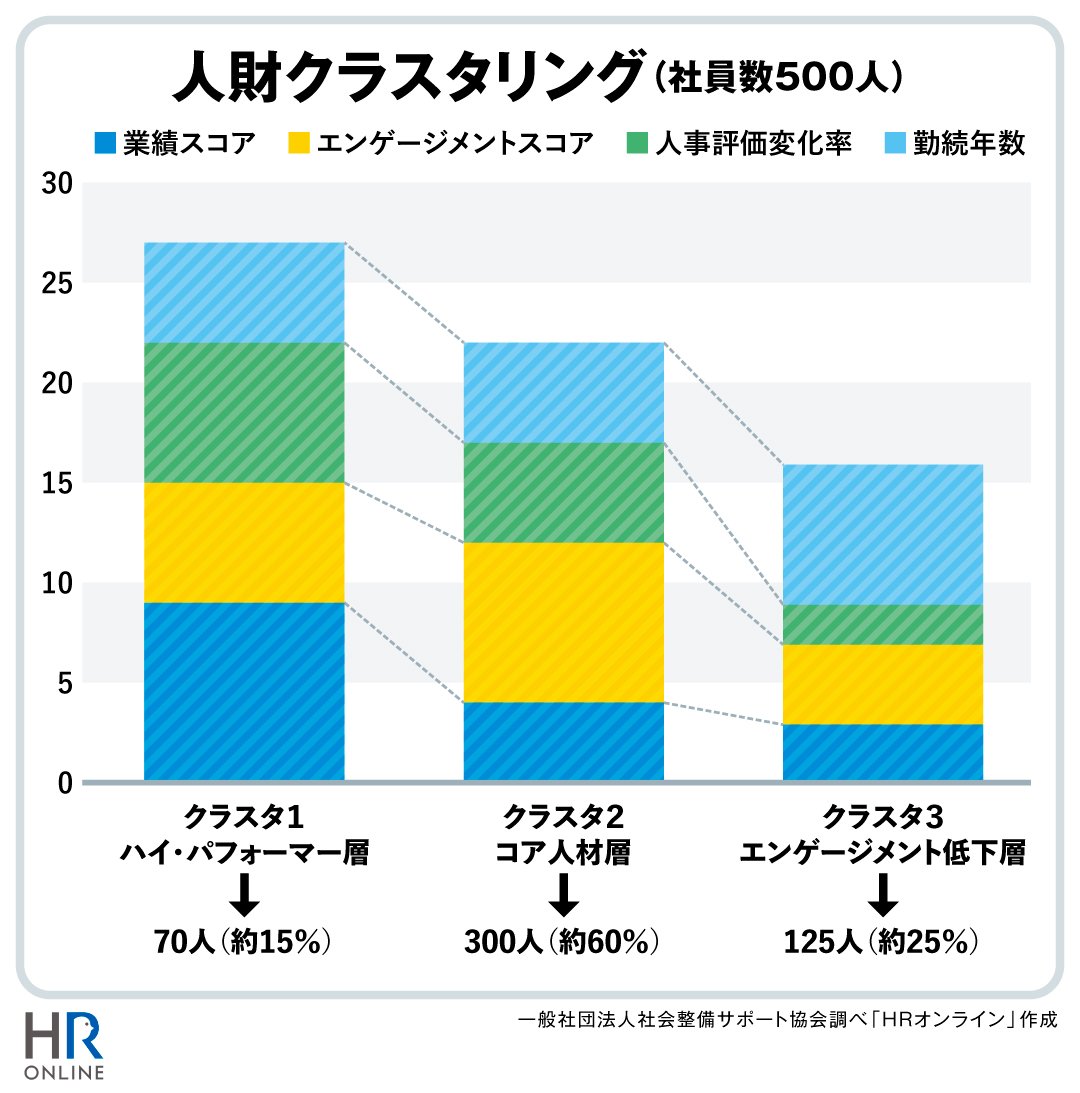
河合 【クラスタ1】は、全変数が高水準で積み上がり、棒グラフが最も高いハイ・パフォーマー層です。変数のうち、業績・エンゲージメントともに高く、人事評価の変化率も正方向(+)で成長を続けています。ただし、エンゲージメントスコアがクラスタ2に比べると低いので、より条件の良い会社への転職リスクが考えられます。抜擢や表彰制度の充実などパフォーマンスに十分に応える施策が必要かもしれません。
【クラスタ2】は、業績はハイ・パフォーマー層より劣るものの、エンゲージメントが最も高く、人事評価の変化率も平均レベルのコア人材層です。実績がずば抜けているわけではありませんが、会社のためによく頑張ってくれています。組織の標準を形成している層であり、施策の費用対効果が最も高い対象といえます。
【クラスタ3】は、エンゲージメントが最も低く、さらに人事評価の変化率が負方向で推移しているエンゲージメント低下層です。勤続年数が長い傾向も見られ、放置すると、離職リスクや業績悪化、ガバナンス上の問題発生につながりかねません。早期の面談・施策が求められます。
このように、エンゲージメントサーベイをそれ単体の結果だけで判断するのではなく、いろいろなデータを組み合わせ、AIを活用することで社員の様子が立体的に可視化でき、具体的に誰にどのような施策を実行すればよいか、打ち手が明確になります。
画一的な人事施策だけではなく、各クラスタに応じた施策を検討するなど、きめ細かな対応によって、社員のモチベーションと生産性の向上を実現し、採用や育成コストを無駄にしない人的資本経営の強化につなげることが可能になります。

人事部門は人に関するデータが豊富に集まる部署ではあるが、そこには注意点もある。特に予測AIでは、事前のデータ準備とデータ加工が鍵を握るという。
河合 どのAIであっても、データの重要性は同じなのですが、予測AIについては、データの質と事前の加工がとりわけ重要です。予測AIの精度は、データ設計と変数設計で8割決まるといっていいでしょう。
やや専門的になりますが、予測AIにおいては「目的変数」と「説明変数」という2種類のデータを設定する必要があり、目的変数とは予測したい結果(データ)のことです。これに対し、説明変数は「特徴量」とも呼ばれ、予測結果に影響するデータを指します。どのデータを説明変数(特徴量)として利用するかは出力の精度に大きく影響するため、適切なデータを選ばなければなりません。
そこで重要になるのが「特徴量エンジニアリング」です。特徴量エンジニアリングとは、「生データを、AIが学習しやすい形に変換・加工すること」「どんな情報をどんな形でモデルに渡すか」を設計する作業のことをいいます。エクセルをイメージしてもらうと、縦列が個々の社員番号であるとして、横列には、年齢や残業時間など生データを入れるだけでなく、様々な加工データを加えます。
人事データの分析でよく使う特徴量エンジニアリングとしては、比率系(残業時間÷所定労働時間など)、差分系(本人評価-上司評価など)、回数・頻度系(異動回数など)、経過時間系(最終昇進からの経過月数など)、変化率・傾向系(残業時間の3ヵ月移動平均など)といったものがあります。例えば、先ほどの「クラスタリング」も、例えば、昇格スピード(=勤続年数÷昇格回数)という説明変数も入れると、さらに精度を上げられるかもしれません。
良い特徴量を設定できると、比較的単純なモデルであっても高い予測性能を引き出せ、逆にどんなに高度なモデルでも特徴量が悪いと性能は出ません。








