 古嶋十潤(ふるしま・とおる)
古嶋十潤(ふるしま・とおる)コンサルティング会社やスタートアップのIT系事業会社を経て、2022年12月に株式会社cross-X(https://crossx-10-tf.com/)を創業し、現職。コンサルティング会社在籍時にはパートナーとしてデータ・AI戦略プロジェクトの統括を担い、日系大手企業を中心にデジタル・DX戦略を推進。IT系事業会社在籍時には執行役員・本部長等として経営・事業マネジメントや東証マザーズ上場、資金調達を経験。現在は創業したcross-Xで、大企業のDX推進アドバイザリーやDX人材の育成支援等を担う。京都大学法学部卒業。著書に『DXの実務――戦略と技術をつなぐノウハウと企画から実装までのロードマップ』(英治出版、2022年)。
AIそのものを理解しただけでは、DXの実務で活用することはできません。DXの実務では、前回の第8回で解説したAIのコアとなる「予測モデル」を「機械学習システム」に実装する必要があり、そのためには多くの技術と関係者が必要です。また、その継続的な改善強化および管理・運用には、多岐にわたる知見と経験が求められます。本稿では、機械学習システムを理解するためのポイントについて、要点を絞って解説します。
機械学習システム活用の
成否を決めるもの
機械学習システムの活用は、事業強化・変革において欠かすことのできないアプローチの一つとなりました。
例えば、デジタルマーケティング分野で成果創出の要となるデジタル広告配信において、最有力のソリューションともいえるGoogle広告の活用では、従来は職人技とも呼べるほど細分化した広告配信設定を、手動で行っていました。
しかし現在は、人間の手によって細かく配信設定するのではなく、Google広告に組み込まれたAIがいかに早期に大量のデータを学習し、CPA(Cost Per Acquisition)等の指標の最適化を実現できるように調整するかが、重要となっています。
また、身近なところではスマートフォンに内蔵されている「写真アルバム」にも機械学習システムが活用されています。
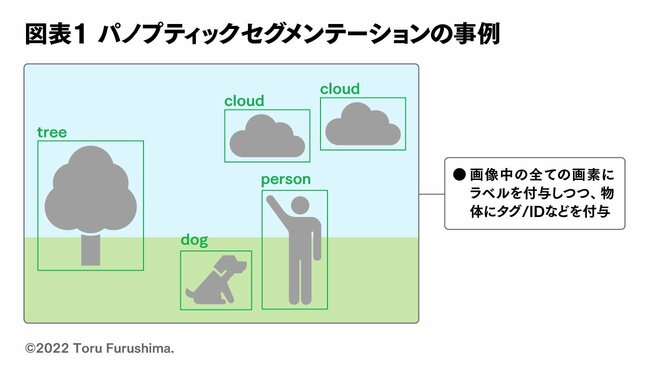
例えば、iPhoneではTransformerをベースとして開発されたAIを用いてパノプティックセグメンテーション(図表1)を実行し、写真の被写体を分類しています。iPhoneユーザーの中には、アルバムを開くと「顔」ごとに写真アルバムが自動で作成されていることに驚いた方も少なくないでしょう。
この点、日々生成される大量の画像データを学習し、予測を実行する一連のプロセスは、機械学習システム内で「自動化」されています。多くのユーザーにサービスを提供するには、単に機械学習システムを構築するだけでなく、可能な限り多くのプロセスを自動化できるかが鍵となります。
機械学習システムを用いて成功を収めているサービスの特徴は、「日々大量のデータが集められること」に尽きます。
例示したデジタル広告配信や画像認識関連のサービスでは、AIの目的は全くと言っていいほど異なりますが、広告配信ログや画像データ収集において「日々大量にデータが生成されている」点では共通します。
いかに高精度の予測モデルを構築したとしても、データによってアルゴリズムの精度を高める「学習」が不十分である場合や、日々変化するユーザーの行動データ等を集めることができない場合、機械学習システムの出力精度は途端に不安定になったり、精度劣化したりします。
一方、常時収集できるデータがあったとしても、そのデータを予測モデルが学習・利用可能な形式に変換できなければ意味がありません。
また、そのデータ処理の作業を「手動」で続けることは物理的に不可能でしょう。この点、データを収集・加工するための技術力や、「自動化」を実現するエンジニアリング力が欠かせません。
さらに、事業活動を通じてWeb経由から収集されるデータ等は、フロントエンドの改修や機能追加などによってデータの構造が変化していくことが通常です。
言い換えれば、データが変化していなければ、ビジネスそのものが停滞している危険性すら読み取れます。よって、データの変化に応じて処理の仕方そのものを継続的に変更していく必要があります。
その状況を察知できないままでは、エラーが発生するなどでシステム全体に影響が生じます。ここで、システムがダウンしたりエラーが頻発したりする状況になってしまうと、サービス利用中の顧客のUX(顧客体験)を著しく毀損します。なお、このあたりの「機械学習システムの設計・運用上の課題」については拙著『DXの実務』で網羅的に解説していますので、ぜひご参照ください。
本稿では「機械学習システムとDX」について解説を進めたいのですが、ビジネス課題の解決策として「本当に機械学習システムを実装すべきかどうか」を考えることは、非常に重要です。
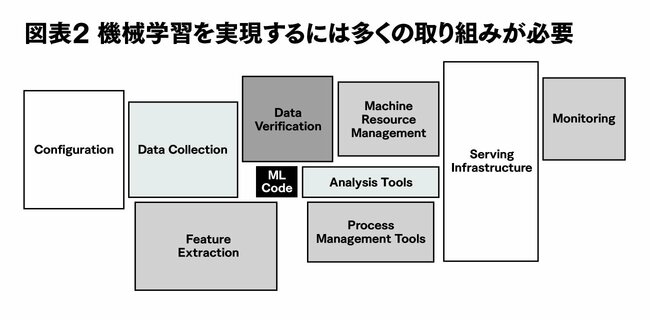
下図は、機械学習の分野で有名な論文、Hidden Technical Debt in Machine Learning Systemsからの引用です。この図が示していることは端的に言って、機械学習を実現するには実に多くの取り組みが必要であり、いわゆる「データサイエンス」が機能する部分はそのごく一部にすぎない、ということです。機械学習には膨大な種類の技術要素が求められるのです。
Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francçois Crespo, Dan Dennison
{ebner,vchaudhary,mwyoung,jfcrespo,dennison}@google.com,Google, Inc.
https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf







