fukuが研究者に実施したヒアリングでは本実験(論文に掲載するデータを取得する実験)までに平均3回以上の予備実験を行っている上に、新しい研究テーマに取り組む際にはこの予備実験の前段階で平均27本の論文を調査し、実験条件の検討に86時間ほどを要していることが分かったという。
特に現場の研究者にとって重たい作業になっているのが、膨大な先行研究の中から自分たちの目的に合致した論文を見つけ出してくること。従来は主に「PubMed」や「Google Scholar」などの論文データベースが使われてきたが、これらのデータベースはあくまで論文をキュレーションしたサービスであり、構造上「内容面も踏まえた検索」が難しい。
著者名や年度などのメタデータで検索するのには向いている反面、本文にしか書かれていない具体的な実験条件を探すのには非効率だというのが山田氏の見解だ。
結果として大雑把なキーワードで対象となりそうな論文にあたりをつけた後は、1つずつ中身を目視でチェックしてエクセルなどにまとめていく必要があるのだそう。それでは作業時間がかかるのはもちろん、論文調査の精度が悪くなることで、予備実験の回数自体が増えてしまうことにもなる。
「人が手探りで調査をしなければならないため、限られた情報源にしかあたることができません。予備実験のスタート地点が悪ければ、どうしてもゴールにたどり着くまでに工数がかかってしまいます。もし過去の研究から自分たちにとって最適なものを抽出してきて正しい判断をする仕組みがあれば、調査にかかる時間を減らせるだけでなく、予備実験の回数自体も減らせるのではないかと考えました。そうなれば、研究者も『創造的な研究活動』により多くの時間を使えるようになります」(山田氏)
そのような背景から、山田氏は冒頭でも触れた論文の横断検索プラットフォームSophiscopeを開発した。
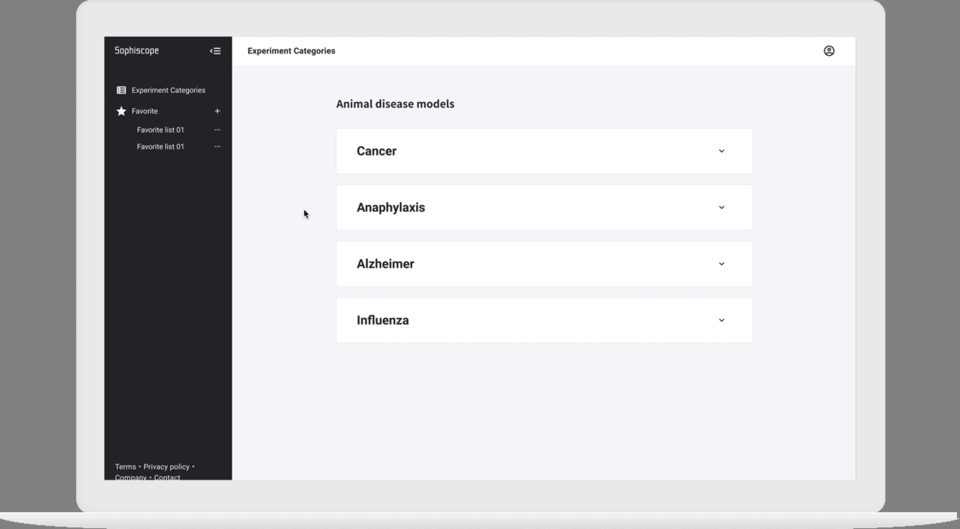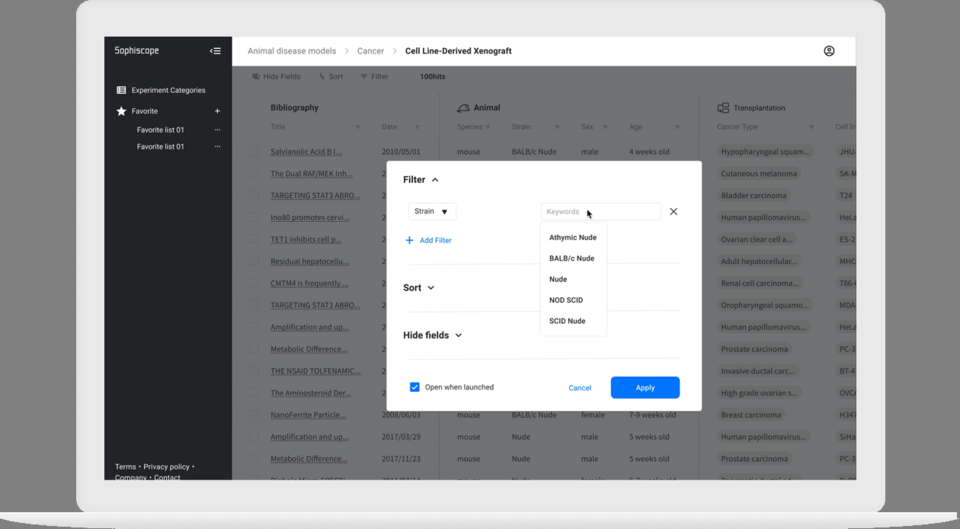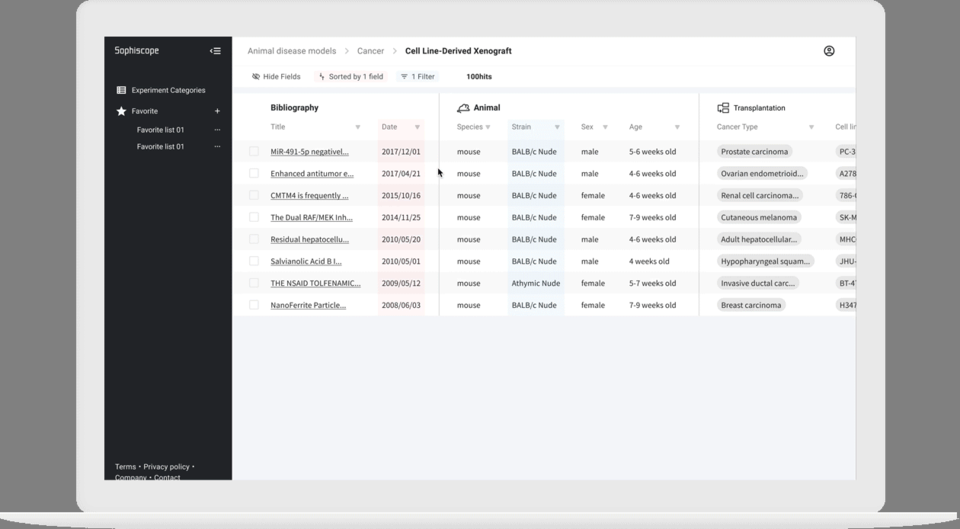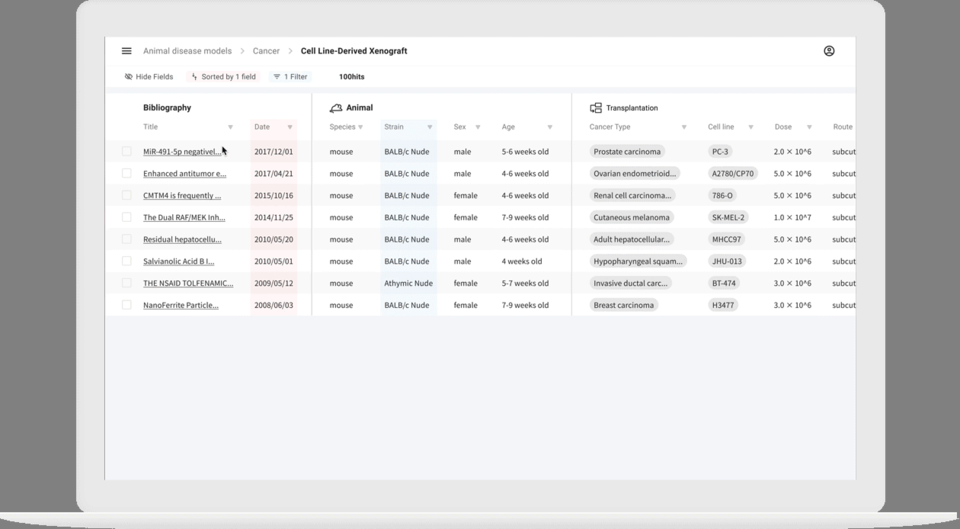
山田氏がポイントの1つに挙げるのが「データの正規化」だ。論文はあくまで人が読んでわかるように人間の言葉で書かれているため、薬の名前やマウスの名前などに関して同じものを指していても表記が異なる場合があり、シンプルな検索エンジンでは検索結果から漏れてしまうことがあった。
そこでfukuでは薬やマウス、がん細胞などそれぞれの要素に対して「オントロジー(言葉の辞書のようなもの)」を用意し、表記ゆれを吸収して検索できる仕組みを整えている。







