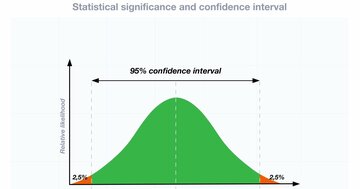
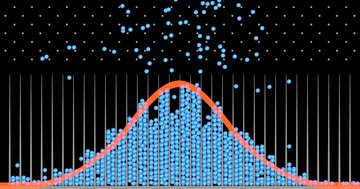
しかし、もっと多くの人を対象にした場合、たとえば500人に本物の頭痛薬を、500人にプラセボを投与した場合は、頭痛薬の穏やかな効果と偶然の変動をはるかに区別しやすくなる。なぜなら、薬の効果(シグナル)は系統的なもので、服用した十分な数の人々に同じ方向に作用するからだ。
一方、ノイズはランダムなもので、薬を飲んだかプラセボを飲んだかとは関係ない状況で、どちらのグループの人も痛みが悪化したり改善したりするだろう。研究の参加者が多ければ、このようなランダムな変動は相殺される傾向があり、したがって大規模なサンプルの平均値は「真の」効果に近いものになる。
統計学者はこれを、「大規模な実験のほうが小規模な実験より検定力が高い」と説明する。そして、新薬がプラセボより本当によく効くなら、グループ間の差を検出できる可能性は高くなる。
検定力は高いほうが望ましい
p値は、ある研究と同じことが実際に起きなかったとしても同じような結果(あるいはそれ以上の素晴らしい結果)が得られる可能性を示すもので、通常はできるだけ低い値(少なくとも、通常は0.05に設定されている標準的な閾値より低い値)が望ましい。
一方で、検定力とは、統計的に有意なシグナルが実際にあった場合にそれを確認できる可能性を示すもので、できるだけ高いほうが望ましい。より小さな効果、つまり弱いシグナルは、十分な量のデータがないと検出がかなり難しいため、普通は求めている効果が微妙なものであるほど、より多くのサンプルが必要になる。
(本稿は、『Science Fictions あなたが知らない科学の真実』の一部を抜粋・編集したものです)
新刊書籍のご案内


スチュアート・リッチー


[著者]スチュアート・リッチー(Stuart・Richie)
心理学者。キングス・カレッジ・ロンドンの精神医学・心理学・神経科学研究所の講師
2015年に科学的心理学会(アメリカ)の「期待の星(ライジンング・スター)」賞を受賞。『タイムズ』『ワシントン・ポスト』『ワイアード』などに数多く寄稿し、BBCラジオなどの出演もある。X(旧Twitter)は@StuartJRitchie.
[訳者]矢羽野 薫(やはの・かおる)
翻訳者
主な訳書に『人間はどこまで耐えられるのか』(河出書房新社)、『運のいい人の法則』(角川文庫)、『ヤバい統計学』(CCCメディアハウス)、『マイクロソフトでは出会えなかった天職』『ザッポス伝説2.0 ハピネス・ドリブン・カンパニー』(ダイヤモンド社)などがある。
英・米メディア騒然の書、
とうとう日本上陸!
既存の本で知ったウンチクを
得意げに語る人に読ませたい、真実の書。