というのも、今までは誰もデザイナーに「頭がサルで体が白鳥というヒトがヘルメットをかぶってコンピュータを操作している絵」なんて依頼したことがないので、比較のしようがないのです。今後は、いろいろな絵がコンピュータによって大量に生成されることになるでしょう。それらの絵は、確実に人間の美的観念やクリエイティブに影響を与えると思われます。
絵の生成に関わる
センシティブな部分
こうした絵の生成はある種、倫理的に本当にセンシティブな部分もあるため、AIの提供企業によっては誰もが使える状態にはしていないところもあります。アーティスト本人が描いたかのような絵が生成されてしまうことや、ポルノ画像のようなものが際限なく生成されることも問題です。また、差別的な意図を反映した画像もいくらでも作ることができてしまいます。そうした倫理面での問題は非常に重要です。
画像がどのように生成されるかという点も、倫理的課題を内包しています。画像生成AIは他のAIと同じく、元の材料となる「学習データ」があります。そのデータを誰かがトレーニングすることによってエンジンができあがります。そこには倫理観が必要です。ここ4〜5年ほどで、AIを提供する多くの企業で「高い倫理観を持って臨むべし」というガイドラインが、一気に整理されるようになりました。
グーグルの年次イベントである「Google I/O 2019」では、AIの倫理についてわかりやすい説明が行われています。彼らが社内外に共有するAI倫理の資料では、機械学習においてどういうバイアスを除かなければならないかが示されています。
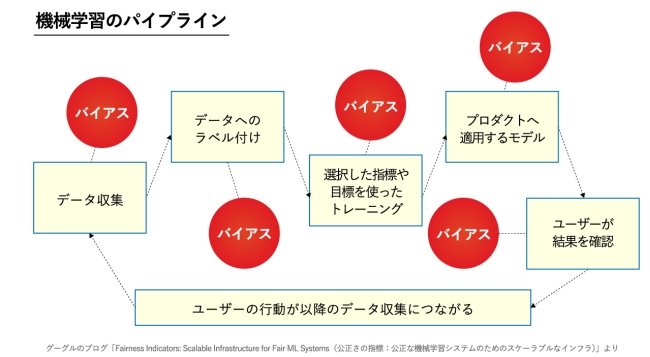
まずはデータに含まれるバイアスです。量が多いデータを正として採用すると、世の中にある多数派による偏見がそのまま助長されてしまうからです。わかりやすい例としては、歴史的に男性が多かった職業の画像をそのまま学習させると、そこで働く人の画像生成を行ったときに男性ばかりが出てくる可能性があります。そうならないようにバイアスを除くわけです。
その他にも説明する事象に付けるラベル(説明)のバイアスや、トレーニングにおける「何が正しいのか」をアルゴリズムに反映する際のバイアス、ユーザーデータのフィルターやランク付け、グルーピングにおけるバイアスなどが挙げられています。
グーグルが開発する画像生成AI「Imagen(イマージェン)」は、こうしたバイアスが排除し切れていないとして、現在、外部には公開されていません。Stable Diffusionなどでは、こうした倫理にかかわる課題を、利用規約上かなり厳しく絞ってクリアしようとしています。







