人工知能やクラウド技術などの進化を追い続けている小林雅一氏の新著、『生成AI―「ChatGPT」を支える技術はどのようにビジネスを変え、人間の創造性を揺るがすのか?』が発売された。同書では、ChatGPTの本質的なすごさや、それを支える大規模言語モデル(LLM)のしくみ、OpenAI・マイクロソフト・メタ・Googleといったビッグテックの思惑などがナラティブに綴られており、一般向けの解説書としては決定版とも言える情報量だ。
この連載では、小林氏による書き下ろしで、ビジネスパーソンが押さえておくべき「AIの最新状況」をフォローアップ中だ。今回は、生成AIの誕生により創業以来の危機が叫ばれたグーグルの現状を、現在進行中の独禁法裁判をもとに解説する。
 Photo: Adobe Stock
Photo: Adobe Stock
グーグルはなぜ訴えられたのか?
米国の司法省と36州の司法長官などがグーグルを反トラスト法(独占禁止法)違反で訴えた裁判が9月12日(米国時間、以下同)、首都ワシントンD.C.の連邦地裁で始まった。約2ヵ月半に渡って続く審理では、「これまでグーグルが端末メーカーと交わした契約が反競争的か否か」が主な争点となる。
他方で「生成AIなど新たな技術が今後IT業界の勢力図をどう塗り替えるか」など将来展望も後々の判決に大きく影響すると見られている。現在グーグルの検索エンジンは米国市場で89パーセント、また世界市場では92パーセントを占めるなど圧倒的なシェアを誇っている。が、今後「対話側の人工知能」など生成AIが検索エンジンに導入されることで、グーグルの一強体制が崩されるとの見方もあるからだ。
初日の審理では、原告側の司法省が「グーグルはアイフォーンなどスマートフォンでデフォルト(初期設定)の検索エンジンとなるために、アップルなど端末メーカーに年間100億ドル(約1兆5000億円)を支払っている」と指摘。こうした反競争的行為によって他の検索エンジンをスマホ画面から不当に締め出していると(する旨を)主張した。
これに対し被告側グーグルの弁護士は「ユーザーはスマホの初期設定を変更して他社の検索エンジンも使うことができる。それでもグーグルの検索エンジンが使われているのは、それが優れているからだ。逆にパソコンではマイクロソフトが(同社の検索エンジン)ビング(Bing)をデフォルトにしているが、多くのユーザーはグーグルを利用している」と述べるなど、初期設定の影響力は小さいと反論した。
また先月26日に開かれた審理では、出廷したアップルのエディー・キュー上級副社長が「幾つかの選択肢の中で、一番優れていると判断されたもの(グーグルの検索エンジン)を選んだだけだ」と証言した。
生成AIを導入してもビング(マイクロソフト)のシェアは伸びていない
10月2日に開かれた審理では、原告側の証人としてマイクロソフトのサティア・ナデラCEO(最高経営責任者)が出廷した。証言台に立ったナデラは「検索エンジン市場に占めるグーグルの独占的な地位があまりにも強固であるがゆえに、マイクロソフト(のような巨大IT企業)でさえ(今のままでは)グーグルと競合するのは至難だ」と訴えた。
今年10月時点でマイクロソフトの時価総額は世界第2位の約2兆4000億ドル(360兆円)と、世界6位となるアルファベット(グーグルの親会社)の約1兆6000億ドル(240兆円)を大きく引き離している。そんな巨人マイクロソフトでも、検索エンジン市場ではグーグルに到底かなわないというのだ。
ナデラはまた、現在立ち上がりつつある生成AI市場についても、グーグルが独占的地位を確立することを懸念していると述べ、その理由として自らの指揮で進めた検索エンジン改革の現状を紹介した。
マイクロソフトは昨年末までに推定30億ドルをOpenAIに出資して、同社のChatGPTやGPT-4等の生成AI開発を支援してきた。その見返りとして、それらの技術を自社のブラウザ「ビング」に導入して対話型の検索エンジンを開発・提供するなど、生成AIの分野ではグーグルに先行してきた経緯がある。
ところが、こうした努力や取り組みにもかかわらず、検索エンジン市場に占めるマイクロソフト(ビング)の占めるシェアはほとんど増加していないという。
実際、米国の調査会社スタットカウンターによれば世界の検索エンジン市場でビングの占めるシェアは今年7月の時点で約3パーセントだが、これは(ビングがGPT-4など生成AIを導入する前の)同1月のシェアと同じである。
今年2月、マイクロソフトが生成AIの技術を導入した対話型ビング(Bing Chat)を華々しくお披露目する記者会見を開いたとき、ナデラCEOは「これでグーグルを踊らせる(=慌てさせる)ことができる」と息まいたが、少なくともこれまでのところはグーグルのシェアをわずかばかりも奪えなかったことを自らの証言で認めた形となった。
もっとも米国のIT専門家やジャーナリストの間で対話型ビングの評判は悪くない。もちろん生成AIに付き物の「誤情報」や「幻覚(情報捏造)」等の問題は対話型ビングでも指摘されているが、他方でその情報アクセスの効率性や使い勝手の良さは高く評価されている。
それでもシェアを伸ばす事が出来なかった理由の1つは、マイクロソフトの戦略的な失敗にあるとの見方が強い。当初、対話型ビングはマイクロソフトIDを有する一部ユーザーに限定して、しかも同社のブラウザ「エッジ」からしか使えなかった。
ブラウザ市場の9割以上はグーグルの「クローム」やアップルの「サファリ」など同業他社のブラウザが占めており、逆に「エッジ」のシェアは1割以下と小さい。つまりユーザー層をあえて限定してしまったことで、マイクロソフトは対話型ビングの発表当時の勢いを自ら削いでしまったと見られている。
生成AI市場でもグーグルが独占的地位を確保するか
こうしてマイクロソフトがもたついている間に、グーグルも今年5月、LaMDAやPaLMなど自社製の生成AI(大規模言語モデル)の技術を応用して、対話型の検索エンジン「SGE(Search Generative Experience:検索生成体験)を開発・提供し始めた。未だ試験運用の段階だが、今年8月末からは日本語でも使えるようになっている。
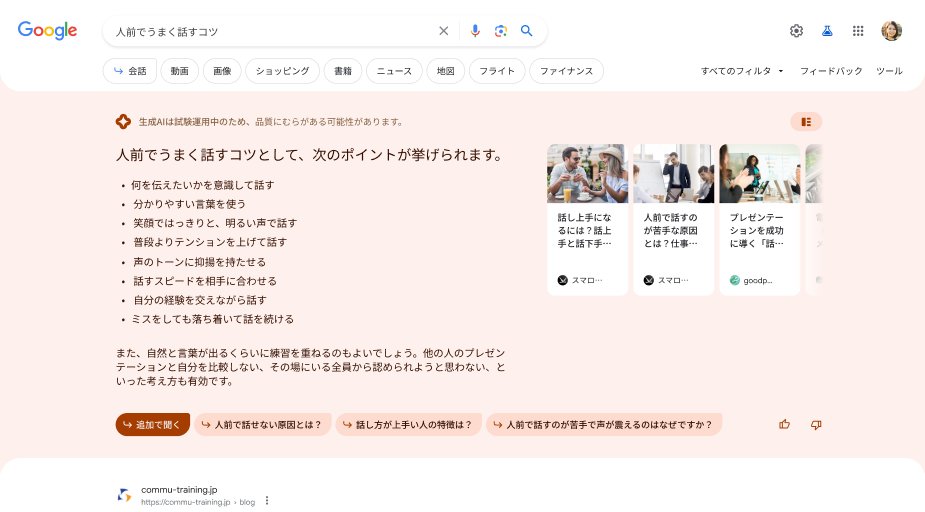 生成AIを導入したグーグルの対話型検索エンジン「SGE」(画像出所:Google Japan Blog)
生成AIを導入したグーグルの対話型検索エンジン「SGE」(画像出所:Google Japan Blog)
ナデラによれば、こうした生成AIを導入した新しい検索エンジンでも、グーグルが引き続き独占的な地位を確保するばかりか、さらにそれを強化する恐れがあるという。
対話型の検索エンジンなど生成AIの技術開発には、大量の言語データを使って「機械学習」と呼ばれる手法でAIをトレーニングする必要がある。そうしたなかで新聞社や出版社などのパブリッシャー(活字メディア)が保有している過去の記事は、特に良質の言語データと見られている。
「グーグルはパブリッシャーに大金を支払うことで、トレーニング用の言語データ(記事)を排他的に取得しようとしている。このままでは(生成AIを導入した)次世代の検索エンジンでもグーグルが独占的な地位を固めてしまう」とナデラは訴えた。
これまでグーグルがアップルなど端末メーカーに巨額の契約金を支払うことで他の検索エンジンを排除してきたのと似たようなことを、次世代の生成AI開発でも繰り返す恐れがあるというのだ。
メディアはできるだけ有利な条件でIT企業と契約したい
一方、これら生成AIを開発するIT企業と対峙するパブリッシャー、あるいはメディア(報道機関)のスタンスは微妙だ。
米新聞大手のニューヨーク・タイムズ(NYT)は今年8月、サービスの利用規約を改訂して生成AIへの対策を新たに盛り込んだ。これまで同社が保有する過去記事など大量の言語データは、米OpenAIの「ChatGPT」など生成AIのトレーニングに無断で利用されてきたが、規約の改定によってそれが禁止された。
これに合わせてNYTは自社サイトでOpenAIのウェブ・クローラ「GPTBot」をブロック(阻止)する措置を施した。GPTBotのようなクローラーは、ウェブ上でGPTなど生成AIのトレーニングに使われる言語データを収集するプログラムだが、今回それがブロックされたことでOpenAIは生成AIの機械学習にNYTの記事を使えなくなった。
これと同様の禁止措置を採用したメディアは、NYT以外にも米国のワシントン・ポストやブルームバーグ、CNN、さらには英国のロイターやオーストラリアのABCなど優に10社を超える
一方これらとは対照的に、米国の大手通信社APのようにOpenAIと正式に契約し、自らの記事をChatGPTなど生成AIのトレーニング用に有料で提供するメディアも出てきた。両社はまた、今後生成AIをニュース報道に活用する方法についても共同で研究していくという。
記事(言語データ)を提供する対価として、どの程度の金額がOpenAIからAPに支払われるかなど、契約の詳細は不明だ。しかし今後、OpenAIが他のメディアとも契約を交わし、その際により高額の使用料金など好条件を提示する場合、APとの契約もそれと全く同じ条件へと自動的に変更される取り決めになっている。
つまりAPは「他社と比べて不利な条件では絶対に記事を提供したくない」と思っている。最も有利な条件で、OpenAIのようなIT企業と契約を結ぼうとしているのだ。
この点については、生成AIへの対抗措置を打ち出したNYTなど他のメディアでも同じだ。これらの企業はそうした対抗措置で当座をしのぐにしても、未来永劫に渡ってChatGPTなど生成AIと敵対するつもりはなさそうだ。
むしろ当面は記事の無断利用を禁止することでOpenAI、さらにはグーグルやマイクロソフト、メタなどの巨大IT企業を交渉の席に引きずり出して、より良い条件で自らの言語データをこれらビッグテックに提供しようとしているようだ。
あるいは最も良い条件を提示したIT企業に対し、排他的に言語データを提供する可能性もある。(前述の)マイクロソフトのナデラCEOの証言は、恐らく現在水面下で繰り広げられている、これらビッグテックとメディアとの間の駆け引きを反映したものであろう。
それはメディア側から見て、やむを得ないことでもある。今後、グーグルやマイクロソフトなどによる対話型の検索エンジンが広く普及すれば、ユーザーの知りたい答えが直接画面に表示されてしまう。
これにより従来の検索エンジンから各種メディアのウェブ・サイトへと流れ込んでいたトラフィックが大幅に減少する恐れがある。それを補う新たな収入源を確保するために、NYTなどメディア側ではデータ使用料をはじめ、出来る限り有利な条件でIT企業と契約したいのだ。
グーグルの独禁法裁判では今後、同社のスンダー・ピチャイCEOら大物経営者も証言する見通しだ。その中で、これら舞台裏の事情がどこまで明らかになるか興味深いところだ。



