生成AIの学習データには
偏りがある
課題の「データの品質とバイアス」とは、機械学習の過程においては、さまざまなバイアスを取り除く必要があるという話です。以前『テキストから画像を生成する「画像生成AI」、なぜ話題で何が課題なのか』の中でも説明しました。
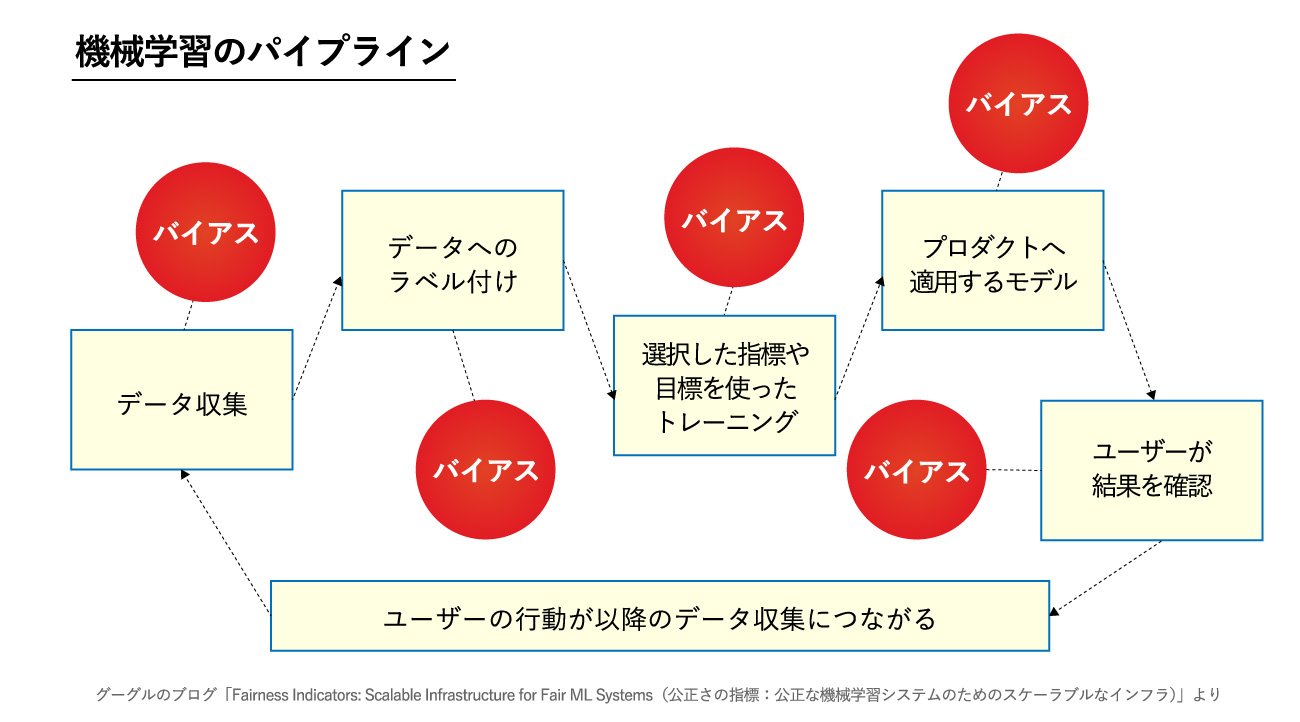 機械学習の過程で取り除くべきバイアス
機械学習の過程で取り除くべきバイアス拡大画像表示
ここで重要なのは「データの偏りは拭いきれない」ということです。
画像生成AIが学習に使用するデータの多くは、1990年代後半以降にウェブ上に公開されたデジタル画像です。極論すると“サイバーパンク的”な画像が生成される傾向が非常に強いのです。AIは江戸時代の浮世絵風の画像も学習してはいますが、学習量がどうしても少なく、画像に偏りが出やすいのです。さらに生成AIが多くのコンテンツを生成するようになると、生成AI自身が生成したデータを学習のために使ってしまうようになり、偏りが増幅しかねません。
このため、AIによる生成データを学習に利用させないよう、コンテンツの来歴をメタ情報でデータに記録しておいて判定しようという取り組みが各社で始まっています。ただし、普及には課題が残ります。また、この方法は画像データでは有効ですが、テキストデータに来歴情報をメタデータとして付加することはできません。このため、AIが生成したテキストをAIが学習することを、現状では止めることができない点も問題となっています。
生成AIは真に創造的なコンテンツを
生み出すことができるか
課題の2つ目、「解釈可能性と透明性の欠如」についても、見ていきましょう。
生成AIは、文字や単語を多次元のベクトル空間に配置して、互いの結びつきや重要度を試行錯誤的に計算した結果、コンテンツを生成します。この仕組みでは「なぜ、ある変数の影響が大きく、別の変数は小さいのか」を誰も説明することはできません。帰納法的に「これがいい」とされるものが選択される仕組みなので、ブラックボックス化してしまうことは避けられないのです。







