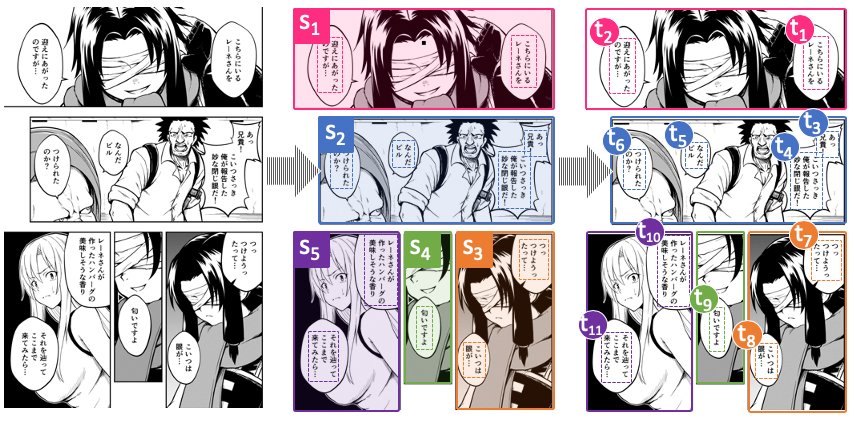
単文ごとに切り分けて翻訳してしまうと、吹き出しを順番に読んでいった際に不自然な訳になってしまうからだ。
人と機械の融合で翻訳スピードを2倍に
Mantraの共同創業者である石渡氏と日並遼太氏(最高技術責任者)は共に東京大学の情報理工学研究科で博士号を取得している。石渡氏は自然言語処理、日並氏は画像認識が専門領域だ。
マンガは絵とテキストが混ざり合っているため「これは誰のセリフなのか」「吹き出しの順番はどうなっているのか」といった情報は、自然言語処理と画像処理の両方を使って認識している。
石渡氏はまだまだテクノロジーを活用できる余地があると感じている一方で、自分たちが研究者であるがゆえに「技術だけではできないことも十分に認識しているつもりです」とも話す。
「ストーリーを考慮しながら、文脈を踏まえて翻訳するのは難しいです。本来はキャラクター性や前巻までのストーリーを加味して翻訳できるのが理想的ですが、まだそこまではできていません。マンガは省略されている情報も多くイラストからそれを汲み取らないといけない時もありますし、人の名前や技の名前など、作品ごとの固有名詞をどのように訳すのかという問題もある。人にしかできないクリエイティブな作業も間違いなく存在します」(石渡氏)
冒頭で触れた通り、Mantra Engineのスタンスは全てを機械で翻訳するのではなく「機械と人間の翻訳家がタッグを組む」ことで翻訳スピードを上げ、より多くのマンガをリアルタイムで世界に届けられる仕組みを実現しようというものだ。
そのためMantra Engineには機械翻訳エンジンだけでなく、翻訳家や出版社・マンガ配信サービス事業者の関係者をアシストするCMS(コンテンツ管理システム)のような機能が搭載されている。
翻訳家は自動翻訳された内容をチェックしながら、ブラウザ上でそのまま修正や校閲をする。今までWordやPDFなどを使いながら何往復もしていた関係者間での確認作業やフィードバックのコメントも、Mantra Engineでは一箇所に集約できるため無駄な作業が少なくて済む。
あくまでMantraが試した結果ではあるものの、従来の翻訳版制作のワークフローと比較してMantra Engineを使った場合には約半分の時間で翻訳版が制作できたそう。これは翻訳作業そのものだけでなく、前後に発生するコミュニケーションやオペレーションが効率化された効果もあるという。
直近では固有名詞の訳し方を「用語集」に登録しておくことで、それ以降の機械翻訳に自動で適用される機能なども追加された。







