「すべての科学研究は真実である」と考えるのは、あまりに無邪気だ――。
科学の「再現性の危機」をご存じだろうか。心理学、医学、経済学など幅広いジャンルで、過去の研究の再現に失敗する事例が多数報告されているのだ。
鉄壁の事実を報告したはずの「科学」が、一体なぜミスを犯すのか?
そんな科学の不正・怠慢・バイアス・誇張が生じるしくみを多数の実例とともに解説しているのが、話題の新刊『Science Fictions あなたが知らない科学の真実』だ。
単なる科学批判ではなく、「科学の原則に沿って軌道修正する」ことを提唱する本書。
今回は、本書のメインテーマである「再現性の危機」の実態に関する本書の記述の一部を、抜粋・編集して紹介する。
 Photo: Adobe Stock
Photo: Adobe Stock
「測定誤差」と「サンプリング誤差」
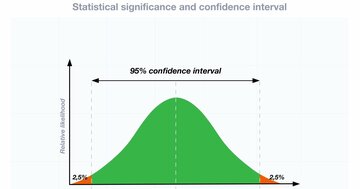
厄介な、「サンプリング誤差」をご存じだろうか。
私たち科学者が、ある現象についてすべての事例を調べることは、皆無ではないにせよほとんどない。対象が1組の細胞でも、太陽系外惑星でも、外科手術でも、金融取引でも同じだ。そこで、代わりにサンプルを抽出して、それをもとに全体を一般化しようとする(統計学では、人間の集合ではなくても全体を「母集団」と呼ぶ)。ただし、抽出したサンプルの特徴(たとえば、全調査対象者の平均身長)が、本当に知りたいこと(たとえば、全国民の平均身長)と寸分たがわず一致することはない。誰が含まれているかというランダムな偶然によって、すべてのサンプルの平均値はわずかに異なる。一部のサンプルは、これも偶然に、全体の真の平均値とは大きく異なるかもしれない。
測定誤差(編集注:実験などの結果を測定する際に生じる誤差)とサンプリング誤差は、どちらも予測できないが、「予測できない」ということは予測できる。異なるサンプル、異なる測定方法、異なるグループから得られたデータは、平均値や最高値、最低値など、ほぼすべてについて多少異なるということはあらかじめわかっている。したがって、測定誤差やサンプリング誤差は、基本的に厄介なものだが、不正なデータを発見する手段として役に立つ。データセットがあまりにも整然としていて、異なるグループ間であまりに似ているときは、何かおかしなことが起きているのかもしれないのだ。遺伝学者のJ・B・S・ホールデンは、「人間は秩序ある動物」で「自然界の無秩序を模倣することは非常に難しい」と述べている。これは私たちにも詐欺師にもあてはまる。