ビッグデータ分析が困難なのは
ID設定に失敗している!?
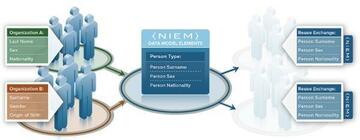
ビッグデータではデータ分析の基礎となる統計手法や、その分析処理を支える分散システム技術に注目が集まるが、それ以外にも重要なことがある。それは ID(識別子、Identifier)である。
IDの割り当てが不適切では、分析にならない可能性がある。仮にデータ分析ができても、非常に手間がかかる。実際、ビッグデータといわれている事例には、ID付けに失敗しているがために、本来は少ない処理で済むところが、大量データ処理、つまり“ビッグ”データになっているケースは少なくない。
ユーザ行動を含め物理世界に関するビッグデータがさかんに使われるようになってきているが、残念ながら、コンピュータは物理世界をそのまま認識することはできない。そのとき物理世界の対象の代わりになるのがIDである。
例えばあなたがSNSにアカウントを持っているとして、SNSにとってのあなたは、あなた自身ではなく、あくまであなたのIDなのである。このとき重要になるのは、分析やサービスの対象にIDを適切に割り当てられていることだ。
IDは多くの場合、番号や文字列となるが、IDを付番するときには原則がある。それは区別したい対象を他と区別できるようにIDを割り当てることだ。言い換えると、IDの割り当て方がよくないと、区別したい対象を区別できない。逆にIDの付け方が細かすぎ、データ分析上、区別しなくてもいい対象も区別してしまうと、分析対象が増えてしまい、分析処理に手間がかかってしまう。
仮にIDの付け方が大まかすぎ、つまりデータ分析上、区別しないといけない複数の対象に同じIDを割り当ててしまうと分析にならない。そして大まかなIDによって区別できない対象を、高度な統計手法を駆使して、間接的に区別しようとすると、その処理量は膨大になる。統計手法や分散処理基盤に頭を悩ます前に、対象に適切なIDを割り当てられているかを考えるべきである。
実商品のA/Bテストを難しくさせる、JANコードの仕様
FacebookやGoogle、Yahoo!など、Webサービスの分野ではA/Bテストというものが広く行われている。例えば、コンテンツやデザインが微妙に違うWebページを用意して、1000人のユーザにはバージョンAを、別の1000人のユーザにはバージョンBを表示して、どちらがクリック数が多いか、購入する回数が多いかを調べ、その結果をサイトの改善につなげているのである。
それでは、ウェブに倣って実店舗でも、同様に商品のA/Bテストはできるだろうか。例えばスーパーで販売される商品のパッケージの絵を微妙に変えた複数の商品を用意して、小売店に並べたとき、どのパッケージがよく売れたかをPOS (Point Of Sales)データから知ることはできるだろうか。
答えはノーである。そしてその理由は商品のIDに帰着する。