ベストセラー『統計学が最強の学問である』『統計学が最強の学問である[実践編]』の著者・西内 啓氏が、ついに待望の新刊『統計学が最強の学問である[ビジネス編]』を発表。ダイヤモンド・オンラインでは、この『ビジネス編』の一部を特別に無料公開。ビジネスパーソンに必要な「統計力」の磨き方について、ヒントをお伝えします。
社内に埋もれたデータを見つけ出す
 「特に活用されていない調査」も、その多くは何らかの経営に影響しそうな理論に基づき、専門家が手間暇かけて作ったものである
「特に活用されていない調査」も、その多くは何らかの経営に影響しそうな理論に基づき、専門家が手間暇かけて作ったものである
アイディア出しが終わったらいよいよ実際のデータを収集しよう。
新規で調査を行なう前に、まず社内にはどのような人材に関するデータがあるか明らかにすることをおすすめする。仮にまだ電子化されていなくても、入社時に提出された履歴書やエントリーシートを見れば、その人がどのような教育を受け、どのような知識と経験を持っているのかわかるはずである。入社年度によって多少形式は変わるだろうが、採用時にSPIなどのテストを受けていれば、従業員それぞれに関する、言語や数の処理に関わる認知能力の指標と、内省性や達成意欲といった性格特性の指標が測定されている、ということになる。
これ以外にも大きな企業であれば、さまざまなシンクタンクやら調査会社から営業を受け、社員のモチベーションやらストレス耐性やらさまざまな項目の調査を導入していることもある。こうした調査はたいていの場合、多少の集計結果だけを報告されて終わり、という以上には活用されていなかったりもするのだが、いざ本書のような枠組みで分析してみると、思った以上に従業員ごとの収益性に影響を与えているのではないか、と示唆されることもある。
こうした「特に活用されていない調査」も、その多くは別にデタラメに作られたものというわけではなく、何らかの経営に影響しそうな理論に基づき、専門家が手間暇かけて作ったものである。毎年定期的に回答しているはずの社員自身でさえ、社内で従業員向けにどのような調査が行なわれているか忘れそうになるが、せっかく分析するのであれば、こうしたデータも活用したい。
アナログな調査だけでなく、社内で管理される情報システムやエクセルシートの中にどのようなデータが存在しているか、というのも大事な視点である。たとえば従業員ごとの勤務日数や、上司からの評定といったデータぐらいは多くの会社でため込まれているはずである。また、プロジェクト管理の行き届いた会社であれば、担当営業の誰が契約してきたプロジェクトについて誰がどのような作業をどれほどの時間担当し、いくらの経費といくらの売上になったのか、といったデータが社内のどこかに蓄積されているはずである。
分析者の立場によっては、必ずしもこれら全てのデータにアクセスできるとは限らないが、匿名化や分析プロジェクトに携わる人員の体制などをうまくコントロールして、可能な限り多様なデータを活用できるように心がけよう。
アウトカムの設定の注意点:データ不足をうまく補う
こうしたデータを揃えたうえで、すでに考えておいたアウトカムとできるだけ一致するような指標はどのように定義できるかを考える。本来なら個人があげた正確な利益が知りたいが、コストに関してはたとえば売上と商品の仕入れ値はわかっても、売上までに至る広告費や接待費などを含まない不完全なデータしかない、という状況が考えられる。このように出した利益の額をアウトカムとして採用することに問題はないだろうか? などと、現実的なデータの制約を考慮したうえで最も良いアウトカムを考えるのである。
そしてアウトカムが決まれば、そのアウトカムと関連することが当たり前、ということにならない説明変数の候補を可能な限りたくさんリストアップする。たとえば成果主義に基づいたボーナス支給が行なわれている会社で、アウトカムを(何らかの)業績に、ボーナス支給額を説明変数にする、というのが「当たり前」になってしまうということである。
おそらく分析結果上、「ボーナスが高い人ほど業績が高い」という結果は得られるだろうが、だからといってただいたずらに従業員に高額なボーナスを支給しても業績は上がらないはずである。こうしたアウトカムとの関連が当たり前になってしまう説明変数は最初から分析すべきではない。
一通りすでに社内に存在しているデータの整理が終わり、その中に必要とするアウトカムや説明変数のデータが不足していれば、次に新規でどのようなデータを調査するか考えなければならない。
ここでは特にアウトカムに関するデータの不足は致命的となる。実際に社内のデータを掘り進んでいくと、本来ならば各従業員の担当したプロジェクトの粗利の総額を知りたいのに、経理システム上、なぜか担当営業が誰かという情報は保持されていないことがある。あるいは、保持されていてもなぜか全て営業部長の名前が入っている、といったデータの限界に気づくこともある。
こうした場合、記憶のある範囲で過去の取引あるいは取引先である顧客をリストアップし、「営業として誰が主に担当したか」という点を関係者に記入してもらう作業が必要になるだろう。
またどうしても利益に関わる金額を従業員個人に紐付けることができない、ということであれば、まったく別の、しかしながら現在利用できる限りにおいて最も妥当に従業員の価値を示すようなアウトカムを考えなければいけない。
たとえば最悪の場合、他に良さそうなデータもないし、上司からの評価をアウトカムとして使うのはどうか、という状況も考えられる。ここで、「上司が正確に部下を評価できそうだよね」という合意が関係者内に得られるのであればそれでも問題はない。しかし、「そうすると上司に媚びるやつのほうが高評価になっちゃいそうだよね」といったことが心配になるようであれば、せめて上司の評価以外に、部下や同僚、取引先の評価の平均値などを取る、いわゆる360度評価の結果を使ったほうがよいだろう。
ちなみに本章でヴィンチュールらによるメタアナリシスの結果を紹介したが、彼らは同じ論文の中で「営業マンの営業成績」だけでなく「上司からの評価」というアウトカムについても同様の分析を行なっている。営業成績に対しては達成性、セールス能力テスト、興味テストが営業職への志向性を示しているか、という3点が重要だったが、上司からの評価で「優秀だ」と思われているかどうかという点では少し結果が異なってくる。
すなわち、達成性という心理特性は実際の業績よりも上司の評価に繋がらない一方、実際の営業成績ではあまり関連の見られなかった一般認知機能(つまりIQ)と、経歴が立派かどうか、という観点が上司からの評価では重要になってくるのである(図表2‐5)。
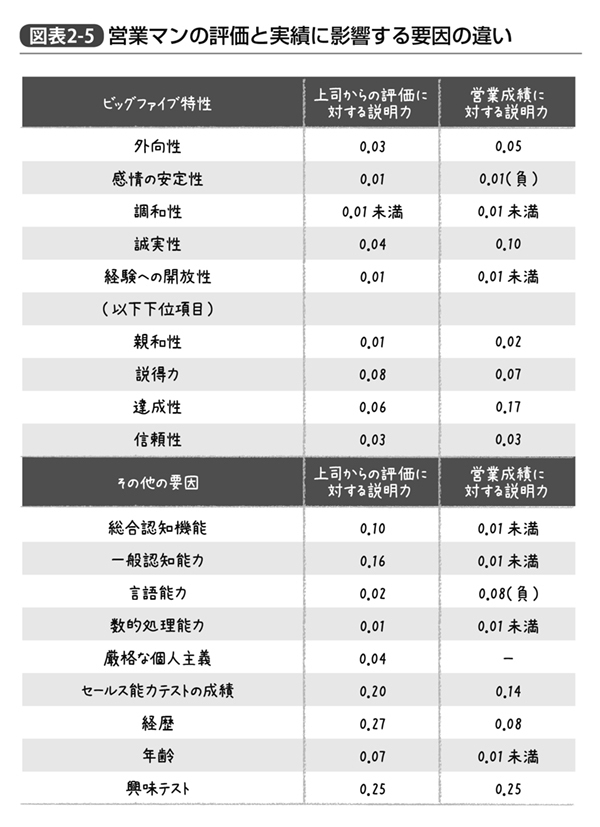
これを素直に解釈すれば、上司は実際の業績云々以上に「知的な受け答えができる立派なキャリアの持ち主」を過大評価してしまう傾向にあるということである。こうした傾向が皆さんの会社内でも存在するのかどうか私は存じ上げないが、「そういう可能性もある」ということを注意しておくにこしたことはない。
説明変数に関わるデータの拡充:性格特性の測り方
アウトカムと比べれば、説明変数に関わるデータの不足、というのはまだ小さな問題であるが、それでもせっかく考えた説明変数がアウトカムと関連しているかどうかわからない、というのは残念な話である。
たとえばいくら関係者一同が「IQ(一般認知能力)なんかより、理不尽な顧客の前で自分をコントロールして商談を冷静に進められるかどうかが大事だよね! わかる!」と意気投合したところでデータがなければどうしようもない。使えるデータには履歴書に書いてある学歴と専門資格のありなし、それと入社時の筆記テストと面接の成績ぐらいしかない、という状況では果たしてセルフコントロールがどれほど業績に影響を与えうるのか、どうやってもわからないわけである。
それでは実際にセルフコントロールを測れるように追加で調査をしよう、ということになるが、これは「あなたは自分をよくコントロールできるほうだと思いますか?」というような質問にイエスかノーかで答えるアンケートを取ればいい、ということではない。
どのような問題を出せば適切にIQが測れるのか、という問題と同様、どのような質問にどう回答させれば性格特性を測定できるのか、という点は、専門的な知識を要する難しい問題である。思いついた質問項目で調査を行なうこと自体が悪い、というわけではないが、人間の性格や心理などの特性を測定しようとすることは、後述の「縮約」など思った以上に難しい問題が背後に存在していることを覚えておいてほしい。
自前で適切な質問項目を作りその組合せで人間の特性を測定するのはたいへん難しい作業だが、それより専門的な心理統計学者たちが作った測定尺度を使って、得られた指標を分析するほうが簡単である。
たとえば、知りたい概念と「質問紙尺度」という言葉を合わせてGoogle検索すれば、案外簡単に心理学者が作った心理測定尺度が見つかる。あるいは、サイエンス社から全六巻の、これまでに作られたさまざまな心理測定尺度を集めた、『心理測定尺度集』という本が刊行されているのでこちらも参考になるだろう。
また近年多くの心理学者たちは「できるだけ少ない項目で正確に心理特性を測れる尺度は何か」というチャレンジをしており、たとえばビッグファイブも10項目の質問で測定できるようになっている。たった10項目ぐらいなら、何かの調査のついでに答えてもらっても大した手間ではないだろう。
仮に尺度自体はよくできた妥当なものであったとしても、それを実際にビジネスプロセスに使えるかどうかとなるとこれはまた別の問題である。たとえば一時期日本でも流行したゴールマンのEQのように、非認知能力を測定する質問紙尺度にはさまざまなものがある。こうした質問紙によってセルフコントロール能力を測ることができる、というのはウソではない。だが、いざ測定したセルフコントロール能力が業績をよく説明することがわかったときに、採用などに使おうとするとどのようなことが起こるだろうか?
IQのテストならいくら受験者が「頭をもっとよく見せたい」と思ってもどう答えればいいかわからないだろう。しかし、セルフコントロールが高いと仕事で成功しやすい、という知識を持った人間ならば、どのように答えれば自分のセルフコントロール得点が高くなりそうか、考えてウソの回答をすることだってそう難しくはないのである。
だとするならば自分での回答ではなく、観察する他者からの評価を使って非認知能力を測ったほうがよいかもしれない。あるいはもっと手の込んだ、意図的なウソのつきにくい実験方法を応用心理学者たちはいくつも考案している。
たとえば「答えの出ないパズルを与えてどれだけの時間ギブアップせずにいられるか」あるいは「バネのついたハンドグリップをどれだけ握っていられるか」という時間を測る、というやり方がある。あるいは、赤い色で書かれた「緑」とか、青い色で書かれた「黄色」など、意味と実際の色が異なる文字を表示された状態で正しく色を認識して回答できるか、というテストもセルフコントロールの測定に使われることがある。何らかの画面を集中して見続けなければいけないテストを出題している横で笑い声付きのコント番組を流され、うっかりそちらに気をとられたり視線をやったりしないか、というようなテストさえある。
もちろん、セルフコントロールを測るためだけに長時間採用希望者に答えの出ないパズルを与えて拘束するのはどうかというところだが、たとえばワークサンプルテストの一環としてこのような課題を紛れ込ませるという手もある。よっぽどのベテランでさえ解決できないような課題を出題し、「あきらめずトライし続けられたか/途中で集中を切らしたり退出したりしたか」といった観点で採点すればある程度こうした非認知能力も反映した評価ができるかもしれない。
ビジネスにおける調査は、学者の研究と違ってクリティカルな損得に繋がる。それは分析しその結果を活用する企業側にとってもそうだが、採用されたい志願者や、待遇をあげてほしい従業員、あるいは有利な取引をしたい顧客にとっても同じことは言える。彼らの中には出てくるデータや分析結果によって直接的な利害がからむ者もいるのだ。そのため、意識してかせずしてか、彼らから多少なりとも偏った答えが出てくるということは当然あらかじめ想定しておかなければならない。
そうした利害にまつわるデータの偏りが出ないよう、あるいは出たとしても補正できるよう、データの取り方自体を工夫することが、人材に関わる分析を行なううえで最も重要なポイントになるのである。
『統計学が最強の学問である[ビジネス編]―――データを利益に変える知恵とデザイン』
 『統計学が最強の学問である[ビジネス編]―――データを利益に変える知恵とデザイン』
『統計学が最強の学問である[ビジネス編]―――データを利益に変える知恵とデザイン』西内 啓著
ダイヤモンド社
定価:1800円+税
累計43万部突破の超人気シリーズに、ついに文系でもわかる「実用書」が登場!
「ビジネス×統計学」の最前線で第一人者として活躍する著者が、日本人が知らない「リサーチデザイン」の基本を伝えたうえで、経営戦略・人事・マーケティング・オペレーションで統計学を使う方法を詳細に解説します。
【ご購入はこちら】
[Amazon.co.jp]
[紀伊國屋書店BookWeb]
[楽天ブックス]
![【新刊無料公開】『統計学が最強の学問である[ビジネス編]』第2章 人事のための統計学(4)](https://dol.ismcdn.jp/mwimgs/2/4/360wm/img_2424295561493df236d175692cd7bcdb452979.jpg)
![【新刊無料公開】『統計学が最強の学問である[ビジネス編]』第2章 人事のための統計学(3)](https://dol.ismcdn.jp/mwimgs/a/4/360wm/img_a49d8ea946f0cc97e9de65d5bc3a5ea0171690.jpg)
![【新刊無料公開】『統計学が最強の学問である[ビジネス編]』第2章 人事のための統計学(2)](https://dol.ismcdn.jp/mwimgs/7/9/360wm/img_7998c021c4f8b8f8a50c5a55c7d68f70332090.jpg)
![【新刊無料公開】『統計学が最強の学問である[ビジネス編]』第2章 人事のための統計学(1)](https://dol.ismcdn.jp/mwimgs/e/c/360wm/img_ec11a0706f1a357b239ff77876a4d68e116826.jpg)