サンプルの量は?偏りは?
その数字は信頼できるのか
元データの偏りはなるべく避けなければならないのですが、元のデータが正しく収集されておらず、分析者がデータの「計測」から始めなければならないケースによく遭遇します。
そもそも、客観的なデータを計測して分析するには図に示すような正しい運用フローが必要になってきますので、それを踏まえていないランキングは何らかの意図によって「ねじ曲げられたランキング」だと考えていいかもしれません。
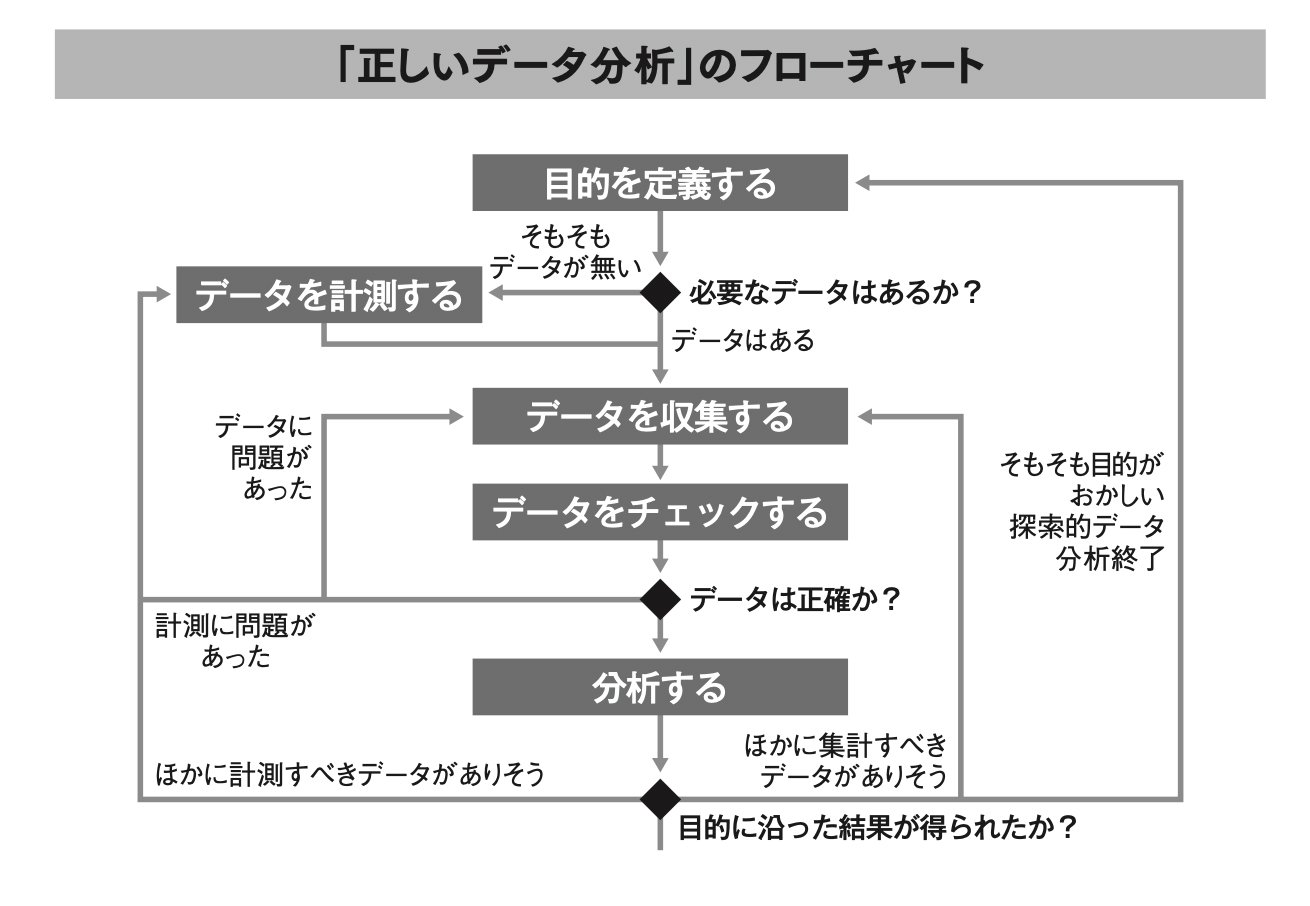 同書より転載 拡大画像表示
同書より転載 拡大画像表示
こういう「データ分析の裏事情」を理解していないから、出来上がったランキングや分析結果を疑わずに鵜呑みにしてしまいやすいのかもしれません。
ランキングを本当に「客観的」なものにしたいのなら、「データなんて簡単に捏造できる」という視点に立って、次の2つの点によく留意する必要があります。
1つ目は「数字の信頼性」です。
「そもそものサンプル数(量)が少ない」、あるいは「サンプル数が特定の年代・場所・嗜好に偏っている」など、ランキングの信頼性を担保するにはサンプルの取り方が重要になります。ちなみに統計学は、サンプルの量と質が担保されていることを証明する学問だと言えます。
新型コロナウイルスにより在宅勤務が強く奨励される中、いったいどれくらいの企業がテレワークに移行できているのか東京商工会議所が調査(期間は20年3月13日~31日)を行い、その結果を20年4月8日に発表しました。
なんとテレワークを実施している企業の割合は、1333社のうち26%と、まずまず高い数字でした。
ただし、調査に答えて欲しいと要請した企業は13297社を数えます。回答した割合から考えると回収率は10.0%と恐ろしいほど低く、実際は「テレワークを導入していない」と回答するぐらいなら、調査に答えないでいようとする意向があったのではないかと勘繰りたくなります。そうなるとテレワークを実施している実際の割合は、相対的にもっと低いのではと考えられます。







